Updating very large tables can be a time taking task and sometimes it might take hours to finish. In addition to this, it might also cause blocking issues.
Here are few tips to SQL Server Optimizing the updates on large data volumes.
- Removing index on the column to be updated.
- Executing the update in smaller batches.
- Disabling Delete triggers.
- Replacing Update statement with a Bulk-Insert operation.
With that being said, let’s apply the above points to optimize an update query.
The code below creates a dummy table with 200,000 rows and required indexes.
CREATE TABLE tblverylargetable
(
sno INT IDENTITY,
col1 CHAR(800),
col2 CHAR(800),
col3 CHAR(800)
)
GO
DECLARE @i INT=0
WHILE( @i < 200000 )
BEGIN
INSERT INTO tblverylargetable
VALUES ('Dummy',
Replicate('Dummy', 160),
Replicate('Dummy', 160))
SET @i=@i + 1
END
GO
CREATE INDEX ix_col1
ON tblverylargetable(col1)
GO
CREATE INDEX ix_col2_col3
ON tblverylargetable(col2)
INCLUDE(col3)
Consider the following update query which is to be optimized. It’s a very straight forward query to update a single column.
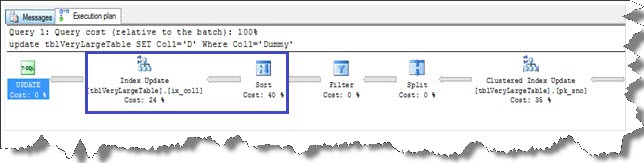
UPDATE tblverylargetable SET col1 = 'D' WHERE col1 = 'Dummy'
The query takes 2:19 minutes to execute.
Let’s look at the execution plan of the query shown below. In addition to the clustered index update, the index ix_col1 is also updated. The index update and Sort operation together take 64% of the execution cost.
1. Removing index on the column to be updated
The same query takes 14-18 seconds when there isn’t any index on col1. Thus, an update query runs faster if the column to be updated is not an index key column. The index can always be created once the update completes.
2. Executing the update in smaller batches
The query can be further optimized by executing it in smaller batches. This is generally faster. The code below updates the records in batches of 20000.
DECLARE @i INT=1
WHILE( @i <= 10 )
BEGIN
UPDATE TOP(20000) tblverylargetable
SET col1 = 'D'
WHERE col1 = 'Dummy'
SET @i=@i + 1
END
The above query takes 6-8 seconds to execute. When updating in batches, even if the update fails or it needs to be stopped, only rows from the current batch are rolled back.
3. Disabling Delete triggers
Triggers with cursors can extremely slow down the performance of a delete query. Disabling After delete triggers will considerably increase the query performance.
4. Replacing Update statement with a Bulk-Insert operation
An update statement is a fully logged operation and thus it will certainly take considerable amount of time if millions of rows are to be updated.The fastest way to speed up the update query is to replace it with a bulk-insert operation. It is a minimally logged operation in simple and Bulk-logged recovery model. This can be done easily by doing a bulk-insert in a new table and then rename the table to original one. The required indexes and constraint can be created on a new table as required.
The code below shows how the update can be converted to a bulk-insert operation. It takes 4 seconds to execute.
SELECT sno,
CASE col1
WHEN 'Dummy' THEN 'D'
ELSE col1
END AS col1,
col2,
col3
INTO tblverylargetabletemp
FROM tblverylargetable
The bulk-insert can then be further optimized to get additional performance boost.
Hope this helps!!!
Like us on FaceBook | Follow us on Twitter | Join the fastest growing SQL Server group on FaceBook
Good General practices…
I don’t think you need to delete the index in question, just DISABLE it. This way you do not have to backup the defination.
Also consider the effect of Transaction Log, with large data modifcations or inserts. Consider the performance impact of Autocommit vs Explicit Commit transaction models. Have a look at http://blogs.msdn.com/b/sqlsakthi/archive/2011/04/17/what-is-writelog-waittype-and-how-to-troubleshoot-and-fix-this-wait-in-sql-server.aspx. Even though his talking about bottle neck on writelog, it still shows interseting point on affects of autocommit on large inserts.
HI Mohit,
Clustered index can not be disabled. And if disabled, underlying table won’t be accessible.
Br,
Anil
Thanks Mohit – yes..disable will be a better option, missed it. I didn’t find significant performance gain with Explicit commit in case of update although it works great for inserts.
Thanks,
Ahmad
I believe you will see a gain in performance if you sort the incoming data by the primary key of the data being updated. I hope this helps.
Hi Dennis – if you are referring to bulk-insert, yes it will increase performance.
Thanks,
Ahmad
Thanks for this post.
For the batch approach, if I need to update a couple of million rows, I then :
– store only the PRIMARY KEY of the tableto get UPDATEd, T1, in another table, T2
– cluster-index that column in T2
– then proceed by taking the TOP X thousand rows ORDER BY the T2 PRIMARY KEY column, UPDATE those in T1, then DELETE those from T2.
This way I can get a constant speed for the UPDATEs 😉
your welcome Nicolas.. only for couple of million rows.. however update+delete will generate lot of t-logs..
want to update a huge table with more than 2000000 row .
here is my code :
DECLARE @i INTEGER
DECLARE @TotalNum Int
DECLARE @Step int
select @Step = round((select count(*) from T1) / 500000,0)
set @i=1
WHILE( @i <=@Step)
BEGIN
Update T2
set SellingPrice = A.maxprice
from T2 inner join
(SELECT MAX(SellingPrice) AS maxprice, Product, Color, Size, DimensionCode, WarehouseCode
FROM T1
GROUP BY Product, Color, Size, DimensionCode, WarehouseCode) as A
on A.Product = T2.Product
and A.color = T2.Color
and A.Size=T2.Size
and A.DimensionCode = T2.DimensionCode
and A.WarehouseCode = T2.WarehouseCode
where T2.SellingPrice =0 or T2.SellingPrice is null
SET @i=@i + 1
END
but this code is still slow
do you have any idea
Hi Nadia – Please share the execution plan for the given query.. also check how much time does it take to update a single record using the query you mentioned, if it takes time then the query needs to be optimized.
Thanks,
Ahmad Osama
Hi Ahmad,
I need to update two columns in three tables, and aprroximate records will be 20K.
So, which approach is better? to use a Stored Procedure or Batch Process?
Hi Megha – you can use any of the above method whether in a procedure or as adhoc parameterised sql query. the batch process can be easily wrapped into a procedure.
Thanks! that was indeed quite informative.
I need to update target table that is around 200 million rows. Source table has around 2 million rows. Both table are matched on the basis of primary key and then update all columns. Total column count is 75 those are being updated.
What can be the best approach to optimize this operation?