Hi Geeks,
Today we will talk about SQL Server Parallelism Operator. SQL Server may decide parallelism to help some expensive queries to run faster which means it decides to use multiple processors simultaneously. In order to make this happen, we should have either two processors or cores or a hyper-threaded setup and in addition affinity mask as well as max degree of parallelism must be configured appropriately.
Let us verify each of these configurations first before going into the topic.
USE master sp_configure


As we see in the above figures, both of these parameters are configured to default value 0 which means they allow SQL Server to use at-least two processors.
Let me run a simple COUNT(*) statement on TransactionHistory table.
USE [AdventureWorks2012] SELECT COUNT(*) FROM Production.TransactionHistory
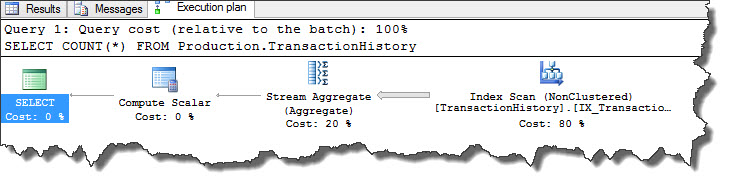
This query plan uses a single worker and is very simple. Execution plan uses Index scan followed by Stream Aggregate (read here Part1, Part2, Part3) and Compute Scalar (read here Part1, Part2) operations. As of now, there is no parallelism operations in query execution. Important point to note here is, Parallelism operation will only be considered when estimated cost of any serial plan is higher than cost threshold for parallelism value configured in sp_configure. Let’s verify configured value for this.
USE master sp_configure

It is set to default value 5 seconds and for the same reason we do not see parallel execution. We will now change this value to 0 for demo purpose then run same query.
USE master --Step 1 sp_configure 'cost threshold for parallelism',0 --Step 2 RECONFIGURE --Step 3 sp_configure

Above figure shows cost threshold for parallelism has been changed to 0 seconds i.e. SQL Server will create a parallel plan for any queries when elapsed time exceeds 0 seconds. We will now run the same query again;
USE [AdventureWorks2012] SELECT COUNT(*) FROM Production.TransactionHistory

From above figure we can observe the presence of parallelism operator. The yellow arrows identify the operations that involve multiple workers where each workers are assigned to a different part of the problem. At the end all partial results are combined then SQL Server produces final result.
Note: This is just an illustration and you should never ever try this method in your live systems.
That’s it for today, you can read all blogs in One operator a day series by clicking here and here is the Index for my execution plan series.
Happy Learning!
Regards,
Kanchan
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook | Follow me on Twitter | Follow me on FaceBook