Hello Friends,
This blog post is the result of question asked by some professionals working on databases. While writing T-SQL code they generally use TOP N in the code to get the top n number of rows in the result set. They knew the another way to achieve the same result by using ROW_NUMBER. Now the question is “Which option is better to use?”. In today’s blog pots we will do the comparison of ROW_NUMBER versus TOP N.
Step 1: Create a database for the test:
USE [Master] GO DROP DATABASE IF EXISTS MayTest; GO CREATE DATABASE MayTest; GO
Step 2: Create a table and insert some data:
USE [MayTest]
GO
CREATE TABLE tbl_RowNumberVsTop
(
RecordID INT IDENTITY(1,1) NOT NULL,
FName VARCHAR(50),
LName VARCHAR(50),
City VARCHAR(100),
DeptID INT NOT NULL
) ON [PRIMARY]
GO
CREATE CLUSTERED INDEX CIX_tbl_RowNumberVsTop_RecordID ON tbl_RowNumberVsTop(RecordID)
GO
SET NOCOUNT ON;
INSERT INTO tbl_RowNumberVsTop VALUES('Kabir','Khan','Gurgaon',3)
GO 1000
INSERT INTO tbl_RowNumberVsTop VALUES('Gurpreet','Singh','Gurgaon',7)
GO 1000
INSERT INTO tbl_RowNumberVsTop VALUES('Prince','Rastogi','Noida',4)
GO 1000
INSERT INTO tbl_RowNumberVsTop VALUES('Robin','Sharma','Delhi',5)
GO 1000
Step 3: Run below queries where first one is using ROW_NUMBER and second is using TOP N to get the same result set, with actual execution Plan:
DBCC DROPCLEANBUFFERS()
GO
DBCC FREEPROCCACHE()
GO
USE [MayTest]
GO
SELECT RecordID
FROM (
SELECT RecordID, ROW_NUMBER() OVER (ORDER BY RecordID) AS RN
FROM dbo.tbl_RowNumberVsTop
) AS T
WHERE T.RN <= 100
GO
SELECT
TOP 100 RecordID
FROM dbo.tbl_RowNumberVsTop
ORDER BY RecordID
GO
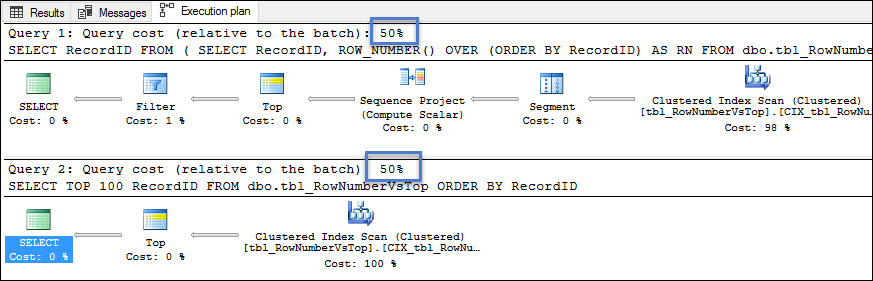
For both the plans estimated cost is similar i.e. 50%. If you will check the estimated number of rows to read in both Clustered Index Scan operators then you will notice that both are showing the same value i.e. 100. We can say that estimated and actual number of rows for both Clustered Index Scan are same i.e. 100.
Step 4: Run queries again but with a small change, specify 1000 number of rows rather than 100, with actual execution Plan:
--Do not run below DBCC commands in production
DBCC DROPCLEANBUFFERS()
GO
DBCC FREEPROCCACHE()
GO
USE [MayTest]
GO
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT RecordID
FROM (
SELECT RecordID, ROW_NUMBER() OVER (ORDER BY RecordID) AS RN
FROM dbo.tbl_RowNumberVsTop
) AS T
WHERE T.RN <= 1000
GO
SELECT
TOP 1000 RecordID
FROM dbo.tbl_RowNumberVsTop
ORDER BY RecordID
GO
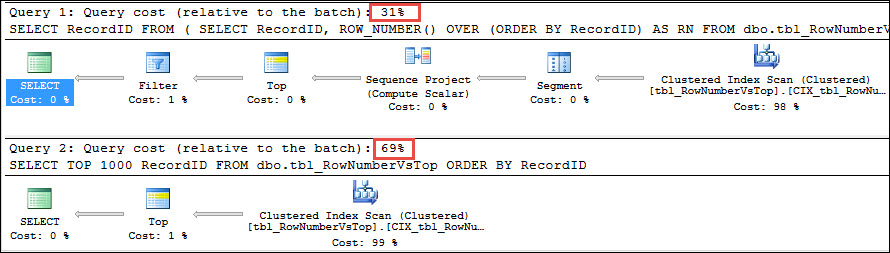
From above screenshot you will say query with ROW_NUMBER is much faster as compare to TOP N i.e. 31% versus 69%. But wait, before any conclusion because the cost you are seeing here is just the estimated cost. If estimates are not correct for operators then query plan estimation cost will also not be correct. Check the properties of Clustered Index scan in both the plans:


You can see that estimated number of rows for query with ROW_NUMBER is 100 while actual is 1000. Query plan estimated cost was calculated based on estimated number of rows i.e. 100. We can not trust on estimated plan cost here. Let’s check the STATISTICS data:

After watching above stats, I can say that take the decision based on statistics data rather than comparing estimated cost of execution plans.
HAPPY LEARNING!
Regards:
Prince Kumar Rastogi
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook
Follow Prince Rastogi on Twitter | Follow Prince Rastogi on FaceBook
so in conclusion we can say, ROW_NUMBER is expensive for big datasets comparing to TOP
and Looking at steps Optimizer took to fetch rows in ROW_NUMBER it is certain that TOp_Number will consume more source.