This article first appeared in the SQLServerGeeks Magazine.
Author: Erland Sommarskog
Subscribe to get your copy.
My tip this month is mainly a tip on style, but if you follow it, a side effect might be that you will be starting to write faster and more correct UNION queries.
We will work with these two tables:
CREATE TABLE dbo.EastTransactions(
TransactionID int NOT NULL,
Name nvarchar(20) NOT NULL,
Qty int NOT NULL,
TransDate date NOT NULL,
CONSTRAINT pk_EastTransactions PRIMARY KEY (TransactionID)
)
CREATE INDEX Name_TransDate_ix
ON dbo.EastTransactions(Name, TransDate) INCLUDE (Qty)
CREATE TABLE dbo.WestTransactions(
TransactionID int NOT NULL,
Name nvarchar(20) NOT NULL,
Qty int NOT NULL,
TransDate date NOT NULL,
CONSTRAINT pk_WestTransactions PRIMARY KEY (TransactionID)
)
INSERT dbo.EastTransactions (TransactionID, Name, Qty, TransDate)
VALUES(1, 'Adam', 20, '2020-01-15'),
(2, 'Tina', 10, '2020-01-16'),
(3, 'Sue', 19, '2020-01-16'),
(4, 'Adam', 20, '2020-01-19'),
(5, 'Pat', 12, '2020-01-22'),
(6, 'Sue', 19, '2020-02-16')
INSERT dbo.WestTransactions (TransactionID, Name, Qty, TransDate)
VALUES(1, 'Ben', 12, '2020-01-12'),
(2, 'Tina', 10, '2020-01-16'),
(3, 'Adam', 14, '2020-01-19'),
(4, 'Pat', 12, '2020-01-25'),
(5, 'Pat', 31, '2020-01-25'),
(6, 'Ben', 14, '2020-01-30')
While these two tables have the same structure, I like to point out that they are from different banks and the transactions IDs are unrelated from each other. The persons are the same, though.
You may know that you can use UNION to combine the result sets of two different queries into a single result set. But are you aware of the fine print? Consider the query below. Before you go on, think for a second or two on what result you expect!
SELECT Name FROM dbo.EastTransactions UNION SELECT Name FROM dbo.WestTransactions
This is the output:
Name -------------------- Adam Ben Pat Sue Tina
Despite that there are in total 12 rows in the two tables, we only got five rows back. If you look more closely, you will see that all duplicates were removed and we got the distinct names.
This is because UNION is a set operator. It takes two sets, and forms the union of the two sets. You may know that relational databases are based on set theory, and in a set, a value cannot appear more than once. Therefore, UNION removes duplicates, not only in the intersection of the two sets (Adam, Pat and Tina), but also duplicates within the individual sets (Sue and Ben).
In case you don’t want duplicates removed, SQL also provides the operator UNION ALL, and if you change UNION to UNION ALL in the query above, you get 12 rows back.
Now, here is an observation: While relational databases are based on set theory, we rarely use them to solve problems with sets as such. Rather, we use them to work with our data. And my experience after all these years with SQL is that in 95 % of the time or so, we don’t want those duplicates removed. It could be that we know that there can’t be any duplicates, or removing the duplicates would simply yield incorrect results. We will see examples of this later on.
I will have to say that I find it unfortunate that the default option, that is, UNION without ALL, is the special case that we only use sometimes. When I see a query that has UNION without ALL, I always get a sense of uncertainty: was the programmer aware of that UNION removes all duplicates when he or she wrote the query? When I write UNION queries myself where I want distinct values, I like to make that clear, so that anyone reading my code understands my intention.
Therefore, I like to introduce this rule to you: Never use UNION, always use UNION ALL. When you want distinct values, and wrap the UNION ALL in an outer DISTINCT query. For instance, if we want to see the distinct persons who have made the transactions in the two banks, the query above should be written this way, according to this rule:
SELECT DISTINCT Name
FROM (SELECT Name FROM dbo.EastTransactions
UNION ALL
SELECT Name FROM dbo.WestTransactions) AS u
This makes it clear to everyone that I want the distinct name, and the output is just not by happenstance.
Always using UNION ALL can also help us with performance. As you may understand, weeding out duplicates is nothing that comes for free, but SQL Server has to spend resources on sorting or removing duplicates by some other means. Consider this query:
SELECT TransactionID, Qty, TransDate FROM dbo.EastTransactions WHERE Name = 'Adam' UNION SELECT TransactionID, Qty, TransDate FROM dbo.EastTransactions WHERE Name = 'Tina'
Since TransactionID is a unique key, and the WHERE clauses qualify different rows, we know that there cannot be any duplicates, so UNION or UNION ALL may not seem to matter. But here is the query plan:
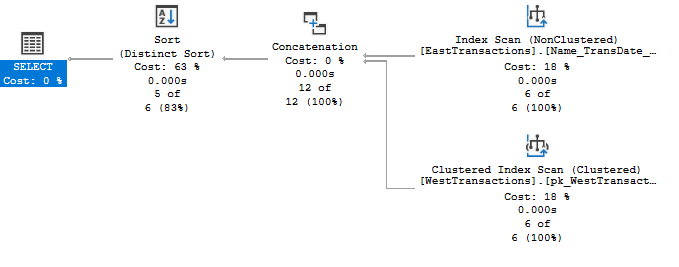
As you can see, the optimizer felt obliged to add a Distinct Sort operator to the plan. You may also note that the operators to the right are both scans. Change UNION to UNION ALL, and the plan looks like this:

There is no Sort operator, and there are Index Seeks instead of scans.
The lesson is that even if you know that the individual queries in your UNION query produces results that do not overlap, SQL Server may not be able to understand this, so you can help the optimizer by using UNION ALL to permit SQL Server to arrive at a more efficient plan.
Carelessly using UNION without ALL, can lead to incorrect results. Say that we want to compute the total quantity for all persons across both banks. We might try this query
SELECT Name, SUM(Qty) AS total
FROM (SELECT Name, Qty
FROM dbo.EastTransactions
UNION
SELECT Name, Qty
FROM dbo.WestTransactions) AS u
GROUP BY Name
That is, we write a UNION query to get Name and Qty from the two banks, and then wrap that in a GROUP BY query to compute the sums. This is the output:
Name total -------------------- ----------- Adam 34 Ben 26 Pat 43 Sue 19 Tina 10
If you go back and look at what’s in the tables, you will find that the result is incorrect for everyone but Ben. This is because Adam, Pat, Tina and Sue all have made two transactions with the same quantity, and when we select only Name and Qty, this results in duplicates that UNION removes. Change to UNION ALL, and we get the correct results:
Name total -------------------- ----------- Adam 54 Ben 26 Pat 55 Sue 38 Tina 20
Some readers may prefer to write one aggregation per table, and then sum up those aggregations in the outer query. You may think that in this case it may not matter if you have UNION or UNION ALL:
SELECT Name, SUM(total)
FROM (SELECT Name, SUM(Qty) AS total
FROM dbo.EastTransactions
GROUP BY Name
UNION
SELECT Name, SUM(Qty) AS total
FROM dbo.WestTransactions
GROUP BY Name) AS u
GROUP BY Name
Not only is this more long-winded and less efficient, since SQL Server has to perform multiple aggregations, but the query also returns incorrect results for one person – can you see whom and why?
Once you have acquired the habit of always using UNION ALL and never use UNION, you will never be making mistakes like this one any more.
I hope to be back with a new tip in the next month of the SQLServerGeeks Magazine!
This article first appeared in the SQLServerGeeks Magazine.
Author: Erland Sommarskog
Subscribe to get your copy.