Hi Friends,
I hope you enjoyed my first post on A refresher on Locks Part 1 where I discussed on Shared SQL Server locks, Update locks and Exclusive locks. Today in Part 2, we will cover following lock types with simple examples under READ COMMITTED isolation level;
- Schema Locks (Sch)
- Intent Locks (I)
- Key-range locks
Schema Locks (Sch) : Schema locks are acquired on object levels in general to protect metadata. There are two types of schema locks;
- SCH-S – Schema stability locks: These are a kind of shared locks and are acquired while compiling queries/generating execution plans. These locks are equivalent to shared locks on object definition. It will block DDL operations on the resource however won’t block normal processing including write operations.
- SCM-M – Schema modification lock: These kinds of locks are obtained during DDL operations such as ALTER TABLE, DELETE TABLE. These locks are incompatible with any other locks like exclusive locks. It blocks access to the object data since structure is being modified.
I’ll create a table for demo and check status on sys.dm_tran_locks DMV, let’s go;
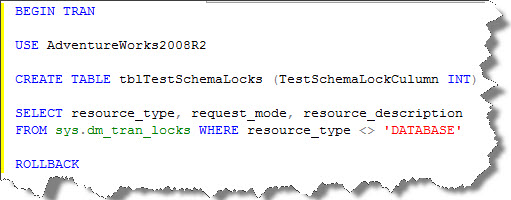
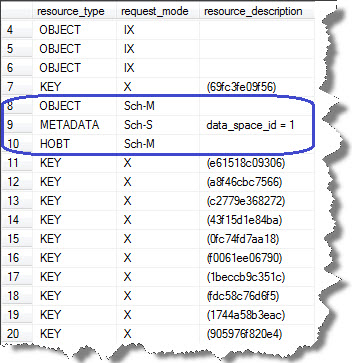
We can observe that Sch-S and Sch-M locks are acquired on system as well as tblTestSchemaLocks with many other locks on the system tables.
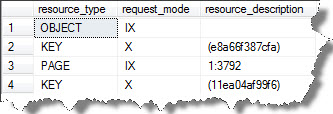
Intent Locks (I) : In simple words, intent locks notifies other transactions that it intends to lock data. By saying that in simple words it means that let’s say, I issue a SELECT statement inside any database SQL Server not only places shared locks on the row(s) that is being read but it will also place an Intent Shared (IS) lock on those pages and the object itself. These locks prevent any other sessions from modifying or dropping the object(s)/page(s) while session is reading that row in question. In my example below, you will observe that Intent Exclusive (IX) locks being placed on the page and the table where the key is to protect data from being locked by any other transactions.

Key-range locks : This lock is used in SERIALIZABLE isolation level to prevent phantom reads. It also prevents phantom insertions/deletions into a set of records accessed by a transaction. With this, SQL Server guarantees rows returned by SELECT statement during a transaction will be same irrespective of number of times they are the SELECT statement is run within that transaction. Let’s try this;
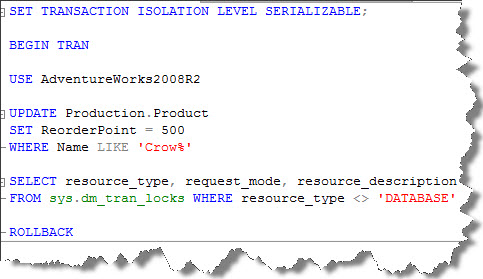
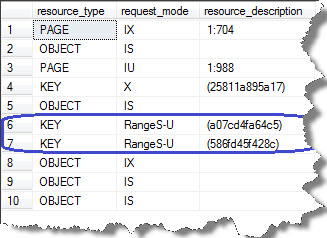
As you see, in my example RangeS-U is placed i.e. shared lock on the interval between the keys and update lock on the last key on the range.
I strongly recommend to read Lock compatibility matrix on MSDN to determine how locks are compatible to each other in SQL Server.
Not to forget, locking depends on transaction isolation levels so you will observe variations when you run them on different environments. I hope refresher Part 1 and Part 2 shed some light how locking operates on SQL Server and help to understand the basics.
Regards
Kanchan Bhattacharyya
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook
Follow me on Twitter | Follow me on FaceBook