Problem Statement:
Theoretically online index rebuild does not block. Practically boom… They do. Online index rebuild operations does not take down your indexes. But there is a point in the index rebuild where they build the new index structure and switch from your old index structure to new one. This is a simple metadata pointer change which requires a Schema-Modify (SCH-M) lock. Coincidentally, SCH-M is not compatible with even a shared lock (S). This results in blocking if your system is a really busy OLTP with heavy reads.
The blocking chain is built on FIFO (first in first out) logic. To understand with an example, let see the following scenario.
Session 51 is running a continuous select. To make it continuous I used the HOLDLOCK hint. This will create a scenario where the select is holding the shared lock for a long time.
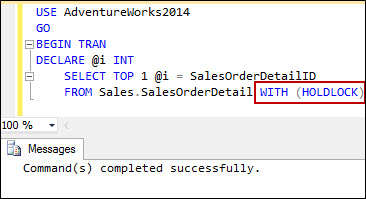
In the session 55 I will run an online index rebuild operation.
USE AdventureWorks2014 GO ALTER INDEX PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID ON Sales.SalesOrderDetail REBUILD WITH (ONLINE = ON)
We can observe that it is getting blocked.
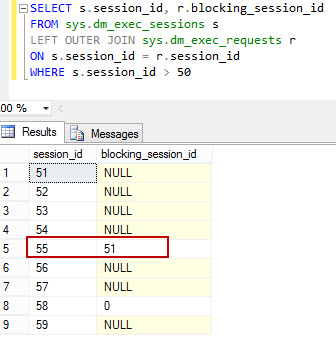
Let us run few more similar select statements and observe the blocking.
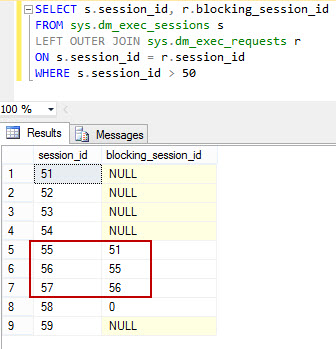
You can see that 51 is blocking 55 -> 56 -> 57 and is building up a blocking chain.
This happens as there are only two queues maintained for managing locks. The grant queue and the wait queue. So when a lock is compatible it gets a grant and executes. If it is not, it gets into the wait queue. In our scenario, the wait queue started with online index rebuild operation. All the other select statements, even though compatible with the shared lock in the grant queue, had to queue up as they are incompatible with the SCH-M lock of online index rebuild operation.
To cleanup, lets us just cancel the online index rebuild, which is quiet obviously not helping in this scenario. All the selects get through once the index rebuild operation is stopped. This is because the shared lock of all the select statements are compatible.
To clear the open transactions I execute the commented COMMIT statement in all the sessions. (Very important when you are doing demo).
Managed Lock Priority – The GEM:
To solve this problem, in SQL Server 2014, we get a brand new queue. This is called low-priority queue. As the name indicates, this queue has lower priority than the wait queue. We can choose to put the operations like online index rebuild into this low-priority queue. This doesn’t change the locking behavior of our operations. It just gives more control on how the waiting priority is managed. Simply put, this is Managed lock Priority which you can control.
There are three options that can be used.
- Kill other processes after MAX_DURATION
- Return to wait queue after MAX_DURATION
- Suicide after MAX_DURATION
The first option may not be suitable for all scenarios and purely depends on type of workload and business decision. The second option gives other select queries MAX_DURATION to proceed without being blocked. But after that time, the DDL operations comes into wait queue and returns back to the old behavior. The third option can be chosen when the DDL operation is not so critical or the other workload is too critical.
So let us see how it works with the same scenario of online index rebuild.
Session 51 starts the long select.
Session 55 runs the online index rebuild operation with the suicide option.
USE AdventureWorks2014 GO ALTER INDEX PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID ON Sales.SalesOrderDetail REBUILD WITH (ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 3, ABORT_AFTER_WAIT = SELF) ) )
The option WAIT_AT_LOW_PRIORITY enables to use the low priority queue.
The MAX_DURATION is always in minutes. So this operation kills itself after 3 minutes.
The ABORT_AFTER_WAIT has possible values of NONE, SELF or BLOCKERS. In this case, specifying SELF will kill itself.
While the index rebuild is getting executed and is blocked, running the other select statements will get through. After the MAX_DURATION which in case is 3 minutes, the operation will kill itself and throw the below message.
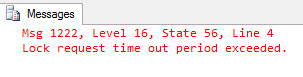
You can try the other options for ABORT_AFTER_WAIT with NONE and BLOCKERS to observe the new behavior. This is one of the hidden gems on SQL Server 2014 which makes the DBA life a bit easier. I will blog about few more, less known gems of SQL Server 2014 in next posts. Till then…
Happy Learning,
Manu
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook |
Follow me on Twitter | Follow me on FaceBook
// To make it continuous I used the HOLDLOCK hint. This will create a scenario where the select is holding the shared lock for a long time.//
HOLDLOCK do not create shared locks.They create X locks on the underlying rows/pages/table.The very step of an online index is that a shared lock in taken on the index. But in your example you are holding X locks which is incompatible with S lock the index rebuild is trying to take, you get a blocking.That’s the reason why with online index rebuilds the index continues to be available because only S locks are taken on the underlying index.
And the Sch-M-Lock is taken only after the version of the source index is created and the data copied to the new index version.It is only then that the Sch-M-Lock is taken on the table to make it totally unavailable so that the table metadata is updated with new index and the version-ed index is copied to the table. Once that’s complete Sch-M-Lock is dropped.
Kindly ignore my previous comment.