Hi Geeks,
In this blog post we will explore on SQL Server Clustered Index Scan operator then try to understand different reason for which SQL Server optimizer picks up this to be the efficient plan operator to return intended records from a table. AdventureWorks2012 is the database used in this example.
SELECT * FROM Person.ContactType
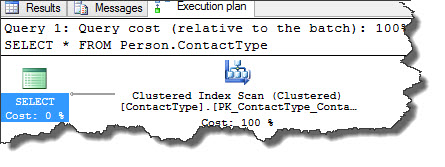
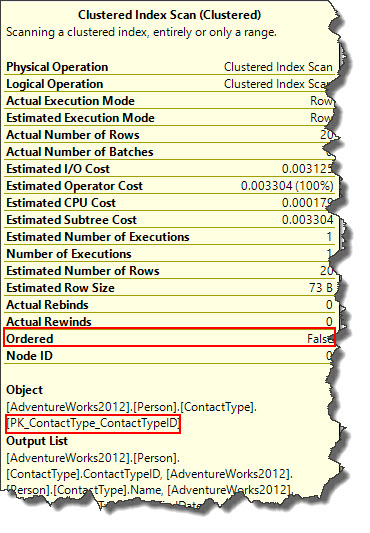
Considering the simple statement used for this demonstration against AdventireWorks2012 database, SQL Server optimizer decided to perform Clustered Index Scan operation. When we place mouse pointer to Clustered Index Scan operator it brings up ToolTip window where we can see that, clustered index PK_ContactType_ContactTypeID was used for this operation.
Clustered Index in SQL Server not only stores structure of the key, it also stores and sorts the data. We can say, a Clustered Index Scan is same like a Table Scan operation i.e. entire index is traversed row by row to return the data set. If the SQL Server optimizer determines there are so many rows need to be returned it is quicker to scan all rows than to use index keys.
Important point to note here is, though it seems both Table Scan and Clustered Index Scan to be similar operations, but former is used for heaps and the later one is used for Clustered Indexes. Using a Clustered Index Scan does not guarantee that results will be sorted and we can observe the same in the ToolTip earlier and is highlighted in red (Ordered property is False). Let us now quickly verify how the behaviour changes when we explicitly add ORDER BY clause in our statement.
SELECT * FROM Person.ContactType ORDER BY ContactType.ContactTypeID
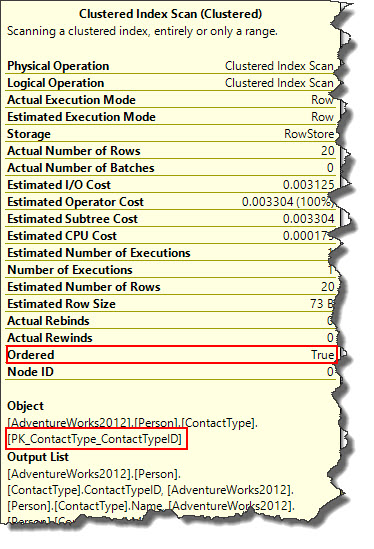
Explanation: By not sorting the result set SQL Server optimizer has the option to find the most cost efficient plan to return requested data. These efficient method include an advanced mechanism known as “merry-go-round-scanning” that allows multiple query executions to share full table scans in order to join the scans at a different location, detailed explanation for which is beyond the scope of this blog post.
Recommendations: If the number of records returned is high, it is good to deep dive and find if there are any possibility to limit the result by introducing appropriate predicates in WHERE clause.
Happy learning.
Regards,
Kanchan
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook | Follow me on Twitter | Follow me on FaceBook