Hi Friends,
This is a common question I face in many of my classes and consulting assignments? The answer is NO. Indexes are B-Tree structures (balanced tree) where navigation/searching happens from top to bottom (root to leaf level) and building the index happens from bottom to top (leaf level to root level).
Whenever you read about Indexes and B-Tree structures, you will always come across the mention of the root page; making you believe that the root page always exists irrespective of the amount of data. Well, that’s not true. If you have data that can be stored in a single page, do you still need a root page? Or do you think that root page may be needed only if you have data that needs to be stored in more than 1 page?
Let us see.
Create a database and a table.
CREATE DATABASE IndexTest; GO USE IndexTest; GO CREATE TABLE example (col1 INT, col2 CHAR (900)); GO
Create a clustered index on the above table.
CREATE CLUSTERED INDEX examplecol1 ON example (col1); GO
Insert enough records that can fit into a single page.
INSERT INTO example VALUES (1, 'Amit Bansal'); INSERT INTO example VALUES (2, 'Amit Bansal'); INSERT INTO example VALUES (3, 'Amit Bansal'); INSERT INTO example VALUES (4, 'Amit Bansal'); INSERT INTO example VALUES (5, 'Amit Bansal'); INSERT INTO example VALUES (6, 'Amit Bansal'); INSERT INTO example VALUES (7, 'Amit Bansal'); INSERT INTO example VALUES (8, 'Amit Bansal');
You will observe that the above 8 records can fit into single page, page size being 8192 bytes. Now let us see how many pages are allocated for this B-Tree structure (remember we had created a clustered inde
Run the DBCC IND command to check the page allocations:
DBCC IND ('IndexTest', 'example', 1);
GO
Output is as follows:
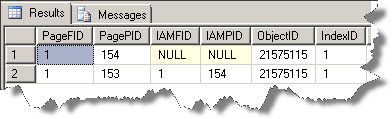
You can see that only 2 pages are allocated, where Page 154 is the IAM page and 153 is the data page which means that there is no root page as of now.
You can also prove this by a very popular DMV:
SELECT *
FROM sys.dm_db_index_physical_stats
(db_id()
, object_id('dbo.example')
, NULL
, NULL
, 'DETAILED');
go
Output is as follows:

Observe that I used the ‘DETAILED’ option in the DMV which gives me output for all the levels in the B-TREE structure and right now there is a single level (index_depth) with a single page (page_count is 1) and this is level 0 (index_level).
Now, let us add another record.
INSERT INTO example VALUES (9, 'Amit Bansal');
Run the DBCC IND command.
DBCC IND ('IndexTest', 'example', 1);
GO
Output is as follows:
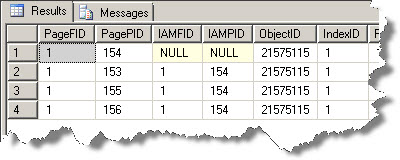
You can now see that page 155 & 156 has been added. We just needed one more page to hold this additional record; then why 2 more pages?
Run the DMV to get the answer:
SELECT *
FROM sys.dm_db_index_physical_stats
(db_id()
, object_id('dbo.example')
, NULL
, NULL
, 'DETAILED');
go
Output is as follows:
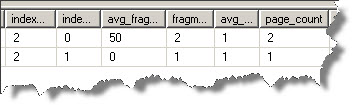
You can observe that index_depth is 2 which means that there are 2 levels now. Level 0 has 2 pages which are the data pages and Level 1 is the root level with a single page. Thus, now we need the root page which has pointers to both the data pages.
You can see that only 2 pages are allocated, where Page 154 is the IAM page and 153 is the data page which means that there is no root page as of now.
I think at that time page 153 is root page and data page.
Hi Pei,
153 is data page only. You can run the following command and see the output of page header which says m_type =1, meaning data page; and even the record type is primary recrod.
DBCC TRACEON (3604);
GO
DBCC PAGE (IndexTest, 1, 153, 1);
GO
Amit, I agree with your answer but I don’t agree with your explaination. when you have one data page in your table, the data page is the root page. You can check it out by using “select * from sysindexes where id = OBJECT_ID(‘example’)” — root column is populated. When you add new records which cause a page split, as you show above, that’s the behavior of root page split. ( the leaf and intermediate level splits behave differently). Why I still agree with your answer — “NO”. because when a table is partitioned, the table will ave one tree for each partition, which means a table has multiple trees.
Hi John,
I understand that the root column is populated but if you run the following command and see the output of page header which says m_type =1, meaning data page; and even the record type is primary recrod. If this was truly a root page, m_type would be 2 and the record type wud show index record. My understanding is that the root page and the intermediate pages contain pointers – not the ‘complete’ data; complete data is obviosuly at the leaf level.
DBCC TRACEON (3604);
GO
DBCC PAGE (IndexTest, 1, 153, 1);
GO
Your perception from the page type of the first page of a b-tree is a data page, thus it can’t be a root. That’s incorrect. because it’s recorded in the system tables and indicated as a root of the b-tree.
John, I am not going by any perception; I am going by the metadata on the page itself which is pretty evident from DBCC PAGE. I buy your point that if there is a B-Tree, there has to be a root. But that one page is the data page itself, not the root page (and I say becusae of the data and metadata contained there in). The moment another data page comes in, a root page gets added and DBCC PAGE for that page clearly says that to be an index page.
Yes, page type is one which is data page but the functions of the this page are exactly same as a root page. Your demo perfectly explained how the root page gets splitted regardless how tall the tree is.
Thnaks John 🙂
There is totally no practical usage of how you call the first page in an index structure. Is it a root page or a “root with data” page. What is the difference?
Hi Alexander; this post is just to explore some internals of indexes in SQL Server; not every thing we write or say can be directly related to practical usage 🙂