Hi Friends,
Today we will see how we can implement Index on HierarchyID Column, and what benefit we can achieve by using these indexes. In My previous blogs on HierarchyID we saw how can we use HierarchyID Column as well as how can we search ancestors and descendant values for HierarchyID column. You can go through on previous blogs by using below links:
SQL Server: Handling Hierarchical data inside the database Part1
SQL Server: Handling Hierarchical data inside the database Part2
There can be two type of search on a tree structure first is Depth First Search as shown below in figure:
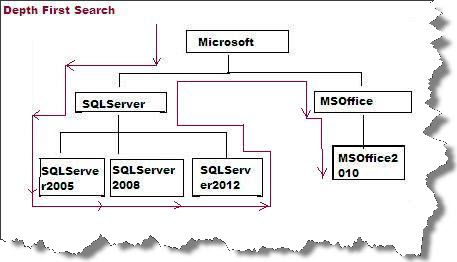
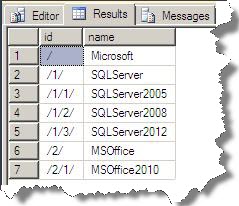
This is also the default behavior of HierarchyID column. In simple words we can say that it will search immediate descendant nodes first .Data is already inserted in the tables from previous blogs mention above. Now just create clustered index on id column here:
USE HierarchyTest go create clustered index IXClus_xthid on xthid(id) go select [id].ToString() as id, name from xthid
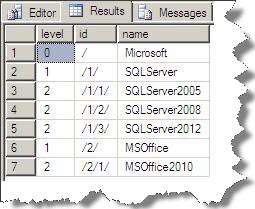
The second type of search on tree structure is Breadth First Search i.e. search will be performing on same level of nodes first. For this you have to add one more column as shown below:
USE HierarchyTest go Alter table xthid add level int go update xtHid set level =id.GetLevel() go select level,[id].ToString() as id, name from xthid
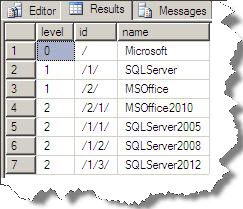
You can think Breadth first search as shown below:

Now we will create clustered index on Level column here to get the benefit of BFS Search.
USE HierarchyTest go Create clustered index IXClus_xthid on xthid(level) with Drop_existing go Select level,[id].ToString() as id, name from xthid
Regards
Prince Rastogi
Like us on FaceBook | Follow us on Twitter | Join the fastest growing SQL Server group on FaceBook
Follow me on Twitter | Follow me on FaceBook
There are two problems here, which one does not suffer if one has a Relational database. There is no need to implement Level as a column. That is (a) hard-coding and (b) breaches Normalisation, which results in an Update Anomaly.
1.Every time a level is added, the Level column in all the rows in the entire table has to be updated. Fine for an example, but not so fine for a real table with millions of rows.
2.SQL is a Data Manipulation language, it does have limitations, but that does not mean that we should not use it properly. You can do everything you require in a single SELECT. The RM states explicitly, that we should not rely on physical ordering; and SQL has an ORDER BY to service our needs. What is wrong with this (assuming you eliminate the Level column and the clustered index for it):
— Vertical or “depth first search”
SELECT [id].ToString() as id,
name
FROM xthid
ORDER BY [id].ToString()
— Horizontal or “breadth first search”
SELECT [id].GetLevel(),
[id].ToString() as id,
name
FROM xthid
ORDER BY [id].GetLevel(),
[id].ToString()
As I stated in the comment on Part 1, it is most important that you understand the data. With that understanding, you can build and navigate a tree, regardless of platform, you do not need funny new datatypes; Without that understanding, no amount of new datatypes and functions will help. And you will end up with Update Anomalies.
Cheers
Derek Asirvadem
@ Derek,
As I said in the comment in Part 1, let’s some some code that supports your position.
@user201713
As I said in Part 1, and above, you need formal education, not code segments. Code segments without the formal education that provides the understanding is meaningless, and leads to a barrage of further questions.
Cheers
Derek
There is more detail re the Level being totally incorrect, in the commentary in Part 1.
Cheers
Derek