Hi Friends,
SQL Server hash match aggregate is selected by query optimizer for the tables with large data and when they are not sorted. Cardinality estimates few groups only and there is no need to sort it.
As an example, TerritoryID column on SalesOrderHeader table has no index and following query will use a Hash Match Aggregate operator.
USE [AdventureWorks2012] SELECT SalesOrderHeader.TerritoryID, COUNT(*) FROM Sales.SalesOrderHeader GROUP BY SalesOrderHeader.TerritoryID
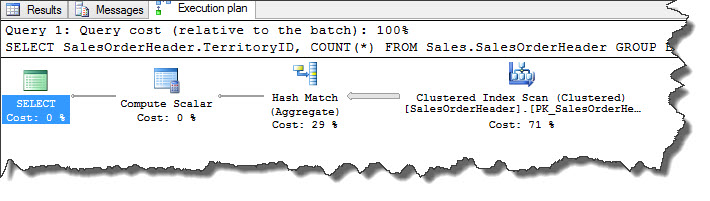
As discussed yesterday, hash operation builds a hash table in memory and hash key used for this table is displayed in properties window which is TerritoryID.
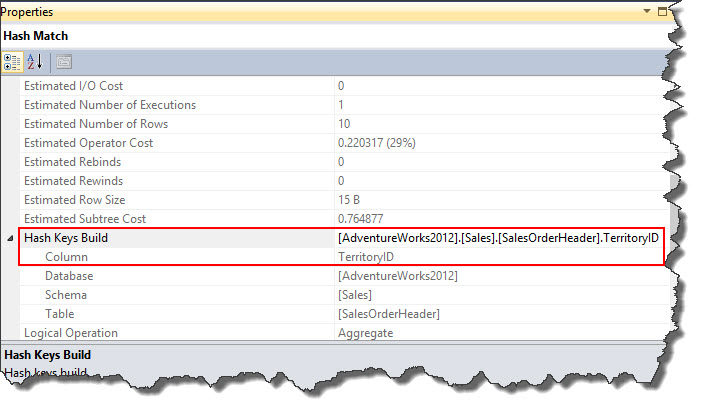
Since this column is not sorted by required column TerritoryID, every row is scanned. Hash aggregate algorithm is almost similar to Stream Aggregate with only exception that, input data is not sorted here.
A hash table is created in memory and a hash value is calculated for each row processed and for each hash value calculated, the algorithm is checked if the corresponding group exist or not, if not it creates a new entry. Values for each record are aggregated in this entry within hash table and you have only one row each group.
That’s all for today, we will continue with hash join aggregate operator tomorrow, till then.
Happy learning.
Regards,
Kanchan
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook | Follow me on Twitter | Follow me on FaceBook