Yesterday we discussed about SQL Server hash match aggregate opertor and today’s post is a continuation of that. If you missed yesterday’s post, you can click here to read it.
Hash aggregate helps when our data is not sorted and if we can create an index on the appropriate column, SQL Server query optimize may use Stream aggregate instead. Let us create an index on TerritoryID column then run same query from yesterday to verify if query optimizer is using Stream aggregate operator.
USE [AdventureWorks2012] --Step1 CREATE INDEX IX_TerritoryID ON Sales.SalesOrderHeader(TerritoryID) --Step2 SELECT SalesOrderHeader.TerritoryID, COUNT(*) FROM Sales.SalesOrderHeader GROUP BY SalesOrderHeader.TerritoryID
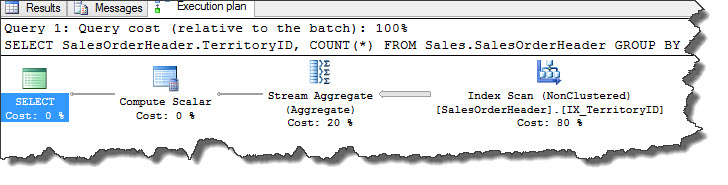

From above images, we can see that after creating a non-clustered index on TerritoryID column, SQL Server query optimizer has chosen to use Stream aggregate instead of Hash Match aggregate. You can read more on Stream aggregate operators by clicking here.
Stay tuned, we are going to explore more on this operator tomorrow.
Happy learning!
Regards,
Kanchan
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook | Follow me on Twitter | Follow me on FaceBook