Hi Friends,
Today I am going to explain about the impact of non clustered indexes on buffer pool or you can also say it as SQL Server key lookup vs index seek operation. Actually this is the continuation of SQL Server Buffer Pool Series. Link is mention below for previous blogs:
Today here we will see impact of key lookup and index seek operations on buffer pool. So let’s start with below code:
USE master
GO
create database PRINCE
GO
USE PRINCE
GO
create table xtbuffertest
(
id1 int not null,
id2 int identity(1,1),
name char(8000),
type char(10)
)
go
create clustered index IX_CLUS on xtbuffertest(id1)
create nonclustered index IX_NONCLUS on xtbuffertest(id2)
go
declare @a int
set @a=1
while @a<31
begin
insert into xtbuffertest values(@a,'SQLServerGeeks','community')
set @a=@a+1
end
go
alter index IX_CLUS on xtbuffertest REBUILD
go
dbcc extentinfo('PRINCE','xtbuffertest')
go
Above code will create a table xtbuffertest on PRINCE database and also insert 30 data rows. Here one clustered and one non clustered index has been created on id1 and id2 columns respectively. If you don’t know about why I alter the clustered index here then go for my this Blog;
Here a single row will fit on single data page due to the columns width. The output of dbcc extentinfo(‘PRINCE’,’xtbuffertest’) will show you about all extent allocation for xtbuffertest table as shown below:
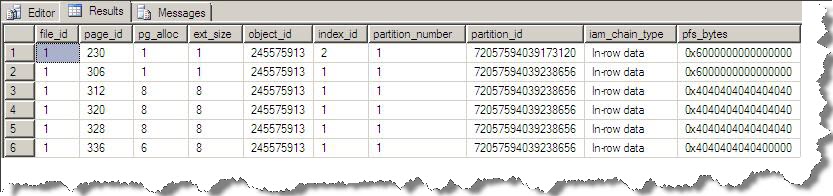
Here 230 id non clustered index page and 306 is clustered index page while line 3,4,5,6 represents extent’s first page id and containing data pages. Now run the below mention query to perform key look up:
USE PRINCE
go
checkpoint
dbcc dropcleanbuffers –-Do not run this command on production server
go
select id2,type from xtbuffertest where id2=2
go
select * from sys.dm_os_buffer_descriptors where database_id=DB_ID('PRINCE') order by page_id
Here first I clear the buffer pool then run the select query. We already created non clustered index on id2 column so SQL Server will use non clustered index due to filter criteria but that non clustered index is not sufficient to serve this query because this query also require data for type column. So SQL Server will perform Key Lookup operation to serve this select query. Here we know page 313 will contain row for id2=2 but SQL Server will read complete extents (data extent + extent which containing clustered index page + extent which containing non clustered index page) as shown below:
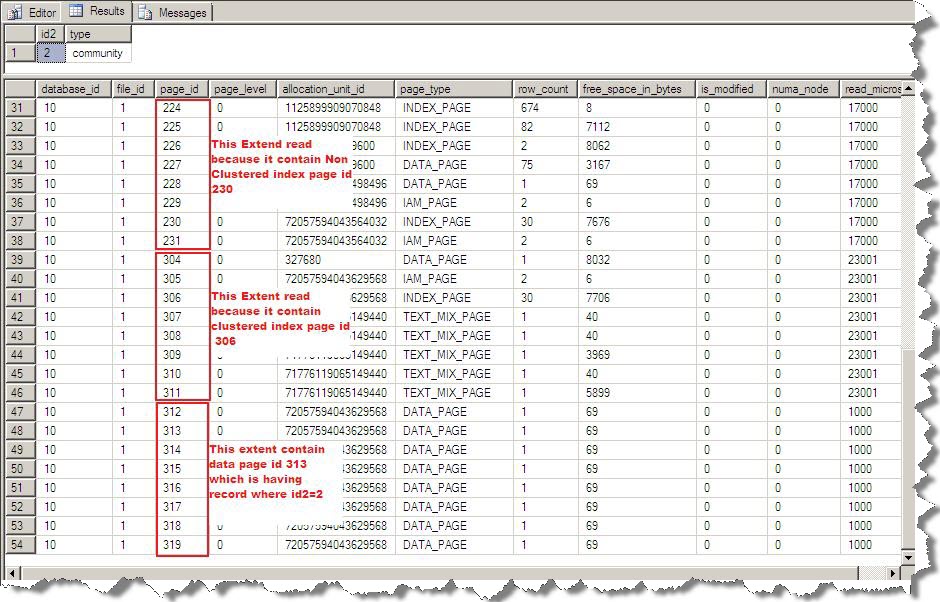
Now if we create a covering index for above select query then it will reduce the extent read by 2 here.
USE PRINCE
Go
drop index xtbuffertest.IX_NONCLUS
create nonclustered index IX_NONCLUSCOVERING on xtbuffertest(id2,type)
go
dbcc extentinfo('PRINCE','xtbuffertest')
go
Now as per the output of above query new Non clustered index page id is 228 as shown below:
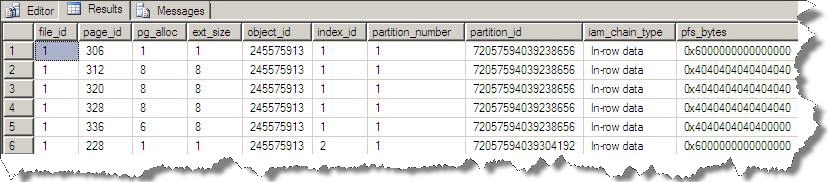
Now again run that same query:
USE PRINCE
go
checkpoint
dbcc dropcleanbuffers –-Do not run this command on production server
go
select id2,type from xtbuffertest where id2=2
go
select * from sys.dm_os_buffer_descriptors where database_id=DB_ID('PRINCE') order by page_id
Here SQL Server will perform index seek operation and will read only extent which is containing Non clustered index page id=228 as shown below:
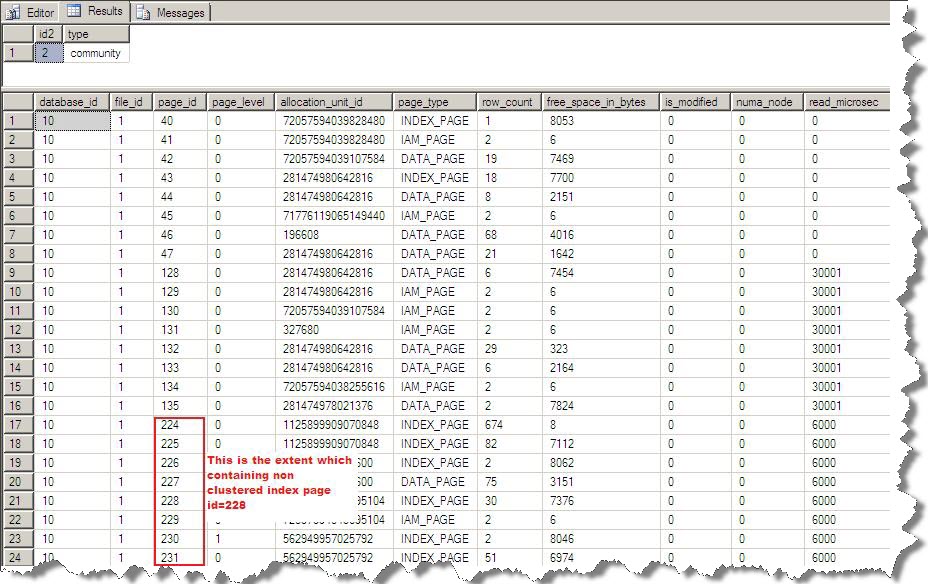
Here we saw that when we use covering index then it reduces extent read by 2.There may be situation like clustered and non clustered index pages both are on same extent then covering index will reduce extent read by 1 (keep in mind that here we perform this test only for selecting the single data row).
Regards
Prince Rastogi
Like us on FaceBook | Follow us on Twitter | Join the fastest growing SQL Server group on FaceBook
Follow me on Twitter | Follow me on FaceBook