Hi Geeks,
If you missed my yesterday’s post SQL Server nested loop join part1, you can read that by clicking here before today’s post.
Let us change our query from yesterday and add a filter on TerritoryID.
USE [AdventureWorks2012] SELECT EMP.BusinessEntityID FROM HumanResources.Employee EMP INNER JOIN Sales.SalesPerson AS SLS ON EMP.BusinessEntityID = SLS.BusinessEntityID WHERE SLS.TerritoryID = 6
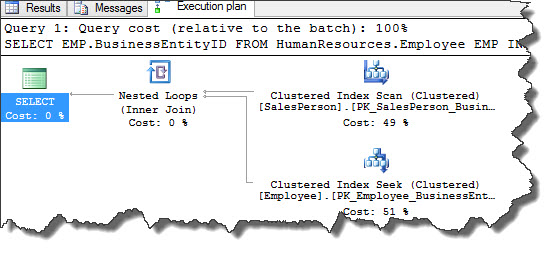
Outer input is again SalesPerson but this time it is not using index scan. The new predicate is using TerritoryID and this column is not part of any index and as such query optimizer decides to perform an index scan. Only 2 records qualify filtering criteria and for the same reason clustered index which is the inner input is executed 2 times.
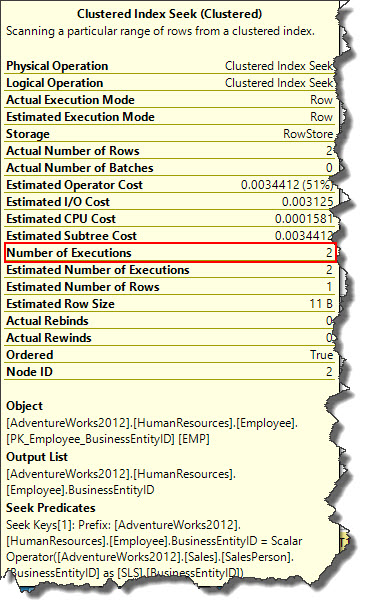
In case of nested loop joins, cost of the algorithm is proportional to the size of the outer input multiplied by the size of the inner input. More likely, this operator is picked by query optimizer when outer input is small and inner input has an index on join key.
That’s it for today, see you tomorrow with a new operator, till then.
Happy learning!
Regards,
Kanchan
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook | Follow me on Twitter | Follow me on FaceBook