Hi Friends,
Welcome to the Part2 of SQL Server query hints execution plan and you can read Part1 by clicking here. Let us start with a simple query. In the example below we have a GROUP BY clause that is used to display count of each City in Address table.
USE [AdventureWorks2012] SELECT ADDR.City, COUNT(ADDR.City) AS 'NoOfCity' FROM Person.Address ADDR GROUP BY ADDR.City

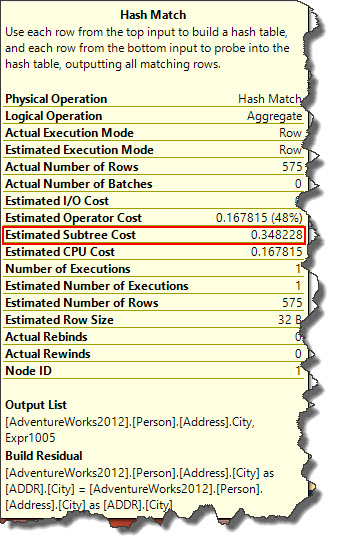
Default choice of the query optimizer to use Hashing. Clustered Index Scan will feed into Hash Match (Aggregate) (read here Part1, Part2, Part3) operator and this operator will build a hash table to select distinct values from index scan then count the values based on matched values. Estimated Subtree Cost of this operator is 0.348228 (this may vary in your environment).
As it is not performing the way we wanted to, let’s say all we want is to eliminate have ordered index scan instead of unordered hash match operation. And to do the same, all we need to do is to modify our query as following;
USE [AdventureWorks2012] SELECT ADDR.City, COUNT(ADDR.City) AS 'NoOfCity' FROM Person.Address ADDR GROUP BY ADDR.City OPTION (ORDER GROUP)
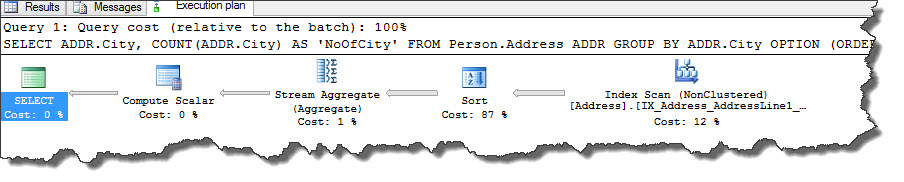
We instructed query optimizer to use ordering in place of hashing. So instead of hash table it is forced to use SORT (read here Part1, Part2) operator which feed the data into Stream Aggregate (read here Part1, Part2, Part3). We see that Estimated Subtree Cost for Stream Aggregate is 1.4876 (this may vary in your environment) which is higher than hashing.
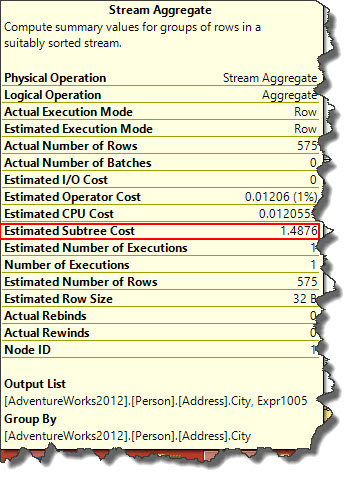
What it means is, though query hints allow you to control behaviour of query optimizer, but that does not guarantee that they will provide you better results.
Note: This is just an illustration and you should try this in live environments.
You can find index to the execution plan series here and click on One operator a day to visit exclusive page for this series.
Happy Learning!
Regards,
Kanchan
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook | Follow me on Twitter | Follow me on FaceBook