Hi Friends,
This one is about SQL Server removing duplicate records in SQL Server 2005 and above. Consider the below table with duplicate records.
Create table tblDup(Sno int identity, Col1 varchar(50))
GO
INSERT into tbldup
values('Value1'),('Value1'),('Value1'),
('Value2'),('Value2'),('Value2'),
('Value3'),('Value3'),('Value4'),('Value5')
GO
The above insert statement is valid only from sql server 2008 onwards. The below code can be used to delete duplicate records from the above table.
- Query 1: Using Row_Number with CTE
;WITH CTE
AS
(
SELECT sno,col1,ROW_NUMBER() OVER(partition by col1 Order by sno) As RowNum
FROM tblDup
)
Delete from Cte Where RowNum>1
- Query 2: Using Row_Number in a subquery
Delete tblsub from ( Select ROW_NUMBER() OVER(partition by col1 Order by sno) As RowNum FROM tblDup ) tblsub where rownum>1
The table tbldup now as 5 unique rows has shown below.

Query1 and Query 2 are similar in performance as shown in the below execution plan.
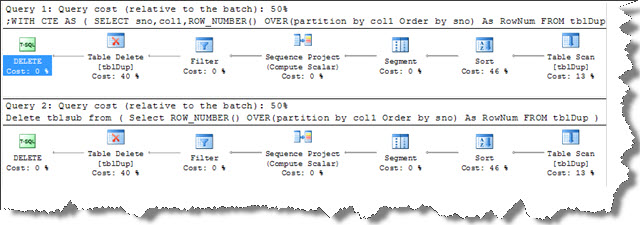
Removing duplicate using above queries can be much slower for large tables having lot of duplicate records. It’s because, lot of T-log entries will be created for the rows being deleted also the triggers and indexes can make delete statement to crawl.The fastest way is to bulk-insert the unique rows into a new table. Bulk-Insert is a minimally logged operation under Bulk-Logged and simple recover model. The code below bulk-inserts the unique rows from the table tbldup into the table tblUnique.
WITH CTEUnique AS
(
Select Sno,col1,ROW_NUMBER() OVER(partition by col1 Order by sno) As RowNum FROM tblDup
)
SELECT sno,col1 INTO tblunique FROM CTEUnique Where RowNum=1
Like us on FaceBook | Follow us on Twitter | Join the fastest growing SQL Server group on FaceBook
Good methodical implementation. I am just thinking how it would be if I used a local temp table instead in CTE. I think it’s worth a try for bulky tables. Thanks.
Thanks Yashpal – for bulky tables I would suggest using bulk-insert.
Yashpal, I prefer CTE over temp tables, because they need not be dropped explicitly at the end. Nevertheless, composing CTE is an art.
Nice example of CTE and it is used a lot in data synchrnization for exactly this purpose. But it is usually just the beginning. The de-duplication of data is way more complex than just removing rows from a single isolated table. Here are a few examples:
1. The table has a children table. In that case we’d have to update FKs first. Not a big deal.
2. PK from our table is used as a reference in an external system. (E.g. DW/BI system). If the data cleansing wasn’t part of the DW project (for this table at least) the ETL has to be modified to handle de-duplication correctly. This can be a big deal, especially if we don’t have a natural key or it is not copied to the external system.
3. Some rows are “similar” and we have to decide if similar means equal and then which one to delete. We can have this case when we have duplicated records of the same person, but each row points to a different address. One is correct and the others are obsolete or incorrect. Do we just keep the latest updated? (If we are lucky enough to have last updated date). Or do we keep the history of changes? Food for thought.
In the real world , duplicates have some logic beyond it ,For example a duplicate product inStock lines caused by different manufacturers of item sending the merchandise. In this case you might want to aggregate the data ( Sum(qty)) with A group by clause , thus, eliminating duplication without deleting any rows of relevant data.