Hi Geeks,
Non-clustered indexes can exist both on heaps as well as objects with clustered indexes and it is possible to have a key lookup on a heap.It is reflected in query plans as SQL Server RID Lookup; following statement will produce same execution plan.
USE [AdventureWorks2012] SELECT * FROM dbo.DatabaseLog WHERE DatabaseLog.DatabaseLogID = 10
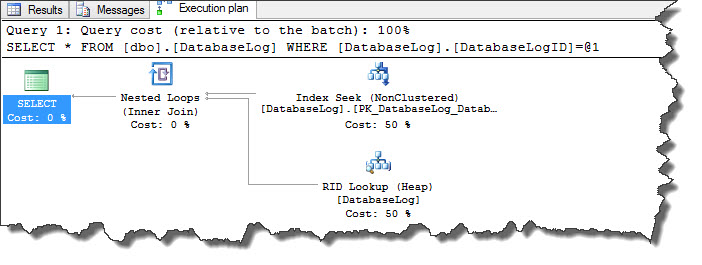
As can be seen, instead of key lookup operator query plan displays RID Lookup operator because heaps don’t have clustering keys as clustered index do and instead they have row identifiers a.k.a RID. A RID is a row locator that includes information like database file, page, slot numbers and helps to identify specific rows quickly. Point to be noted here is, every row in a nonclustered index that is created on a heap contains RID of the corresponding record.
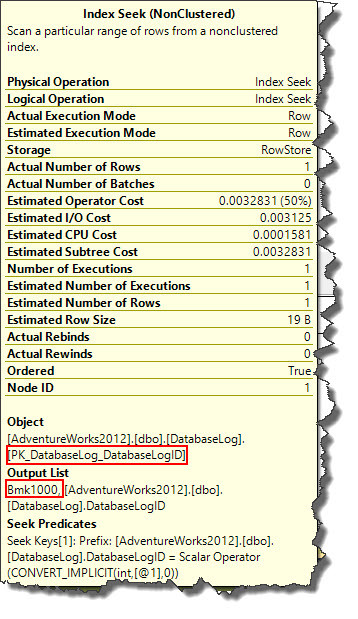
To return the results for the statement used in our example, SQL Server query optimizer performs an index seek on the primary key PK_DatabaseLog_DatabaseLogID (see image above). As highlighted Output list of index seek operator contains ‘Bmk1000’ which tells us, all the data columns needed to be returned by the statement weren’t part of the key and hence query optimizer performed a RID Lookup.
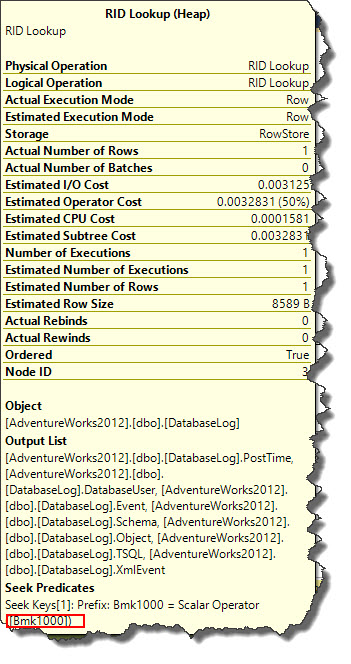
This an additional I/O overhead as two different operations are performed instead of a single one. This time ‘Bmk1000’ used again and in Seek Predicate section which tells us a bookmark lookup was used in query plan.
If result set is small, then this isn’t anything to be worried about but if RID lookup returns many records we should start looking at re-writing the query or to define appropriate clustered or covering index.
Both key lookup and RID lookups are accompanied by a nested loop join which we are going to cover in future.
Happy learning!
Regards,
Kanchan
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook | Follow me on Twitter | Follow me on FaceBook
Wonderful Post and great beginning Kanchan !!! Thanks for your service!!!