In this blog, we are going to be diving into The Concept of Density.
What is Density?
Density is defined as the measure of the uniqueness of the data in a column. This implies that density is measured on a per column basis. In other words, density can also be defined based on how often we encounter duplicate values.
The value for Density ranges from 0 to 1.0, which can be obtained using the following formula
Density = 1/(number of distinct values in a column)
(Or)
Density = Average number of duplicates for a certain value/Total row count.
High density would imply that there is less unique data in the column, whereas low density would imply that the data present in the column is more unique.
We will be using AdventureWorks2014 database for this demo.
The table named SalesOrderHeader has two particular columns of special interest to us that are RevisionNumber & TotalDue.
USE AdventureWorks2014
GO
SELECT RevisionNumber
,TotalDue
FROM Sales.SalesOrderHeader
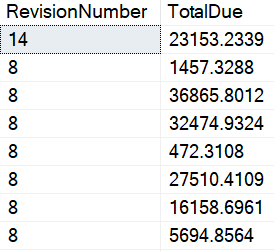
RevisionNumber has multiple duplicate values, while TotalDue contains a variety of values thus making it the more unique of the two.
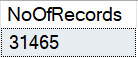
First, let’s check the total number of rows in the table. There are 31465 records in the table.
SELECT COUNT(*) NoOfRecords FROM Sales.SalesOrderHeader
Next, a SELECT statement is executed (as shown below), to count the number of distinct values present in the column TotalDue.
SELECT COUNT( DISTINCT TotalDue) AS DistinctTotalDue FROM Sales.SalesOrderHeader
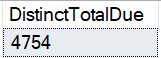
There are 4754 unique entries in the column TotalDue. Having obtained the value, it can be applied in the formula to get the Density of that specific column.
Density = 1/4754
= 0.000210
0.000210 is the density factor for the column TotalDue.
Next, repeat the same process on RevisionNumber, it is seen that there are only 2 distinct values in the entire column and thus the density factor will be greater than the previous case.
SELECT COUNT( DISTINCT RevisionNumber) AS DistinctRevisionNumber FROM Sales.SalesOrderHeader
Density = 1/2
= 0.50
0.50 is the density factor for the column RevisionNumber.
Density is used by the query optimizer when it is evaluating multiple plans and of course also in the case of cardinality estimation. For this blog, we will take the column TotalDue as an example and attempt to understand where exactly is the value of density stored.
Let’s manually create STATISTICS for the column TotalDue.
CREATE STATISTICS TotalDue ON Sales.SalesOrderHeader(TotalDue) GO
Next, execute a statement to display the statistics for TotalDue as shown below.
DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader', TotalDue) GO
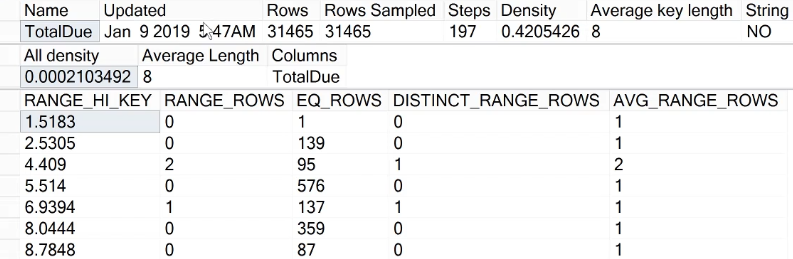
There are multiple columns of information here, including a particular record that provides us with the density, which is 0.0002103492, the same number obtained from the calculations earlier.
How the query optimizer uses this piece of information to calculate the Cardinality Estimation is beyond the scope of this blog, but rest assured there will be a blog soon addressing this particular topic. So, stay tuned!
Let’s drop the statistics we created earlier for this demo.
DROP STATISTICS Sales.SalesOrderHeader.TotalDue