Hi Friends,
This is my 31st blog on SQL Server Trace Flag 2389 in the series of One Trace Flag a Day. You can go to all blogs under that series by click here.
Trace flag 2389, provided by Microsoft to change the behavior of SQL Server optimizer. This trace flag was introduced in SQL Server 2005 SP1. Till now, we all know below things about SQL Server:
- By default, SQL Server triggers auto update on statistics based on threshold values. If you want to know about these threshold values then click here.
- By default, SQL Server also tracks the status of statistics leading column that can be Ascending, Stationary or Unknown. By default, no action will be taken by SQL Server on the basis of this status information. If you want to know more about this then click here.
- By default, if you will run a select query to get the column(s) values from all the rows which have been inserted after the last statistics update then SQL Server estimates them as only 1. This happens because SQL Server doesn’t have information about those inserted rows in the statistics. I will show you this behavior in this discussion later.
If you want to change the default behavior described in 3rd point then you can use trace flag 2389. This trace flag should only work if below condition satisfied:
- Leading column of your statistics (Which is going to be used by optimizer for your query plan) should be marked as Ascending by SQL Server.
- A covering index should exist with the ascending column as leading key.
Now let me show you the above behavior without trace flag 2389.
use master
go
--Enable the trace flag to check the default behavior
DBCC TRACEON(2388,-1)
go
--Drop this database if alreay exist
if DB_ID('StatsDemo2014')>0
begin
Alter database StatsDemo2014 set single_user
Drop database StatsDemo2014
end
go
--Create a database for Demo at default files location
Create database StatsDemo2014
go
Use StatsDemo2014
go
--Create table
create table xtstatsdemo
(
id int not null identity(1,1),
name varchar(25)
)
go
--create non clustered index on id column
--this will generate statistics on this index with the same name as of index
create nonclustered index IX_xtstatsdemo_id on xtstatsdemo(id,name)
go
------ First Block to insert data and update the stats --------
insert into xtstatsdemo values('SQLServerGeeks1');
go 10000
update statistics dbo.xtstatsdemo with fullscan;
go
------ Second Block to insert data and update the stats --------
insert into xtstatsdemo values('SQLServerGeeks2');
go 750
update statistics dbo.xtstatsdemo with fullscan;
go
------ Third Block to insert data and update the stats --------
insert into xtstatsdemo values('SQLServerGeeks3');
go 200
update statistics dbo.xtstatsdemo with fullscan;
go
------ Fourth Block to insert data and update the stats --------
insert into xtstatsdemo values('SQLServerGeeks4');
go 50
update statistics dbo.xtstatsdemo with fullscan;
go
DBCC SHOW_STATISTICS('xtstatsdemo','IX_xtstatsdemo_id')
Go

Till now, we have a table with 11000 rows and one statistic object due to non clustered index where ‘id’ is a leading column. Statistics also has been updated and leading column in statistic has been marked as ascending (which is pre required condition for working of trace flag 2389) by SQL Server. Now we can say that as per statistics, SQL server has information about all 11000 rows. Now let me try to insert 1288 more rows i.e. below the auto update threshold value.
insert into xtstatsdemo values('SQLServerGeeks5');
go 1288
So, no auto update statistics will trigger i.e. SQL Server don’t know about these newly inserted rows. Now let see what happen in execution plan, if I will select columns from only these newly inserted rows. You can enable Include Actual Execution Plan from management studio or by pressing CTRL+M.
Select id,name from xtstatsdemo where id>11000 go
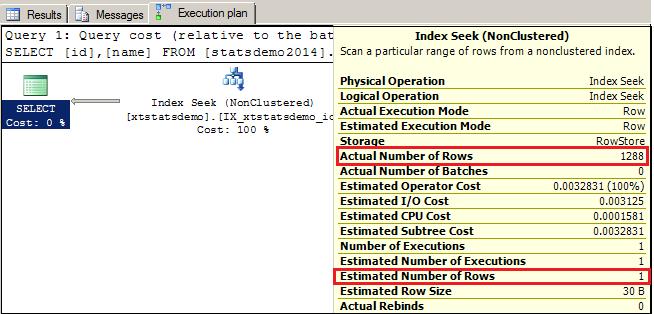
From the above execution plan, you can see that SQL Server estimated number of rows as 1 because it does not have any information about those 1288 new inserted rows in the statistic object. While actual number of rows is 1288. So it’s a big difference in estimated and actual number of rows. This can create a performance issue for large tables because resource allocation for query execution depends on this estimated number of rows. Keep in mind that this default behaviour is not applicable on SQL Server 2014 because of new cardinality estimator. Now let me show you the query plan for same query after enabling the trace flag 2389.
DBCC TRACEON(2389,-1) go --OPTION(RECOMPILE) used to create a new plan Select id,name from xtstatsdemo where id>11000 OPTION(RECOMPILE) Go
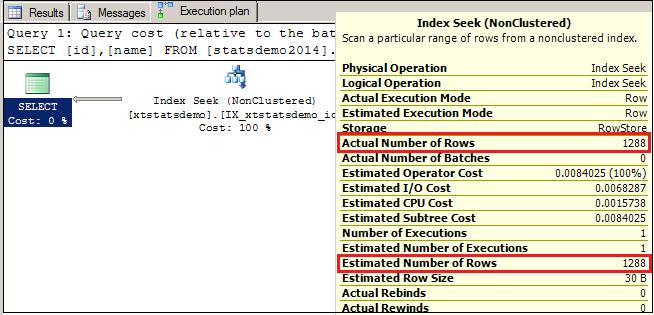
Now from above execution plan it is clear that Actual and Estimated number are same here. This is good for performance perspective.
Do not forget to turn off the trace flags.
DBCC TRACEOFF(2389,-1) DBCC TRACEOFF(2388,-1)
PS: Do not use trace flags in production environment without testing it on non production environments and without consulting because everything comes at a cost.
HAPPY LEARNING!
Regards:
Prince Kumar Rastogi
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook
Follow Prince Rastogi on Twitter | Follow Prince Rastogi on FaceBook