Hello Geeks and welcome to the Day 3 of the long series to come in One DMV a day. In this series of blogs I will be exploring and explaining the most useful DMVs in SQL Server. As we go ahead in this series we will also talk about the usage, linking between DMVs and some scenarios where these DMVs will be helpful while you are using SQL Server. For the complete list in the series please click here.
Today I will be talking about sys.dm_db_missing_index_details. Along with this DMV I would also be using sys.dm_db_missing_index_columns. The first one is actually a DMV and the second one is a DMF which uses the index_handle from the first DMV to provide details that will help you in building the index. Both these DMVs are mostly used together to get the missing indexes on tables which may help in improving the performance.
First let’s see how it collects what indexes are missing on a table. When a query is run against a table the query optimizer generates a plan and looks for the best fit of indexes. If the best fit is not available it generates a sub optimal plan but saves the best index details. Yes, if you are already visualizing what I am telling many of you would have already got the below picture in mind.
Apart from displaying this it also saves this information in the DMV sys.dm_db_missing_index_details. This information is available only till the instance is up and is refreshed when the instance is restarted. So as a best practice, dump this data into a tacking table time-to-time to collect what indexes are missing which are needed for better performance.
Let us create a scenario that will help us understand how to use sys.dm_db_missing_index_details and sys.dm_db_missing_index_columns. First create a database and a table in it and populate the data. This query may run for some time as it is populating 1 million rows.
CREATE DATABASE TEST_Missing_Index GO USE TEST_Missing_Index GO CREATE TABLE employee(id INT PRIMARY KEY CLUSTERED, Mid INT, salary INT, joining_Date DATETIME) GO DECLARE @i INT = 1 WHILE (@i < 1000000) BEGIN INSERT INTO employee SELECT @i, CASE WHEN @i > 5 THEN @i%5 + 1 ELSE 1 END, (@i/100000)*10000, DATEADD(yy,-@i%10,GETDATE()) SET @i = @i + 1 END
Now if you run the below statement you would not see any rows.
USE TEST_Missing_Index
GO
SELECT * FROM sys.dm_db_missing_index_details WHERE database_id = DB_ID('TEST_Missing_Index') AND object_id = OBJECT_ID('employee')
So let’s run some the below queries to get some missing index details in the DMVs.
USE TEST_Missing_Index GO UPDATE employee SET salary = 1000000 WHERE salary = 0 UPDATE employee SET Mid = Mid WHERE Joining_Date < GETDATE() - 10
Now run sys.dm_db_missing_index_details and sys.dm_db_missing_index_columns DMVs and pass the two index_handles (1, 3) from first DMV to the second DMV as below.
USE TEST_Missing_Index
GO
SELECT * FROM sys.dm_db_missing_index_details WHERE database_id = DB_ID('TEST_Missing_Index') AND object_id = OBJECT_ID('employee')
SELECT * FROM sys.dm_db_missing_index_columns(1)
SELECT * FROM sys.dm_db_missing_index_columns(3)
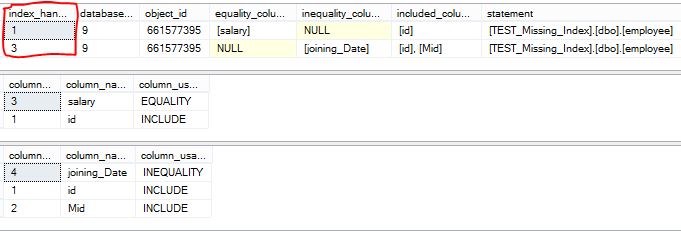
Now what do we interpret from this result? There are three important columns in sys.dm_db_missing_index_details which are further explained in detail in sys.dm_db_missing_index_columns. These are equality_columns, inequality_columns and included_columns. So the indexes that are missing should have the equality columns (columns compared using “=” condition in where clause) in the beginning of the index key, inequality columns (columns compared using <, >, etc. in where clause) to the end of index key and included columns (columns in select list) in the included columns of the index. So the index missing would be the below two. Again creating these indexes depends on the frequency of queries of similar kind run on this table.
CREATE NONCLUSTERED INDEX Missing_Index_1 ON [dbo].[employee] ([salary]) INCLUDE ([id]) GO CREATE NONCLUSTERED INDEX Missing_Index_3 ON [dbo].[employee] ([joining_Date]) INCLUDE ([id],[Mid]) GO
The data collected in these DMVs is very RAW and should not be the only consideration when you are building missing indexes. As per MSDN there are some limitations in this data collected by sys.dm_db_missing_index_details.
- Up to 500 missing indexes data can be stored.
- In case of multiple columns in a missing index the order is not specified.
- Cost information is inaccurate for inequality columns.
- Filtered indexes are not suggested by this DMV.
- The cost information varies for same query data collected at different times.
- Trivial query plans are not considered.
So as a good DBA you know you have to collect this data regularly and make wise decisions when using this data for building missing indexes. Tomorrow I will talk about another DMV. Till then
Happy Learning,
Manu
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook | Follow me on Twitter | Follow me on FaceBook
Hi Manohar,
Thanks for the wonderful series. We are learning a lot.
I have a question, When we query sys.dm_db_missing_index_details, it will give output of so many missing indexes of tables. How do we decide adding what all indexes will be useful?
Regards,
Aman Ankit
The answer is in the blog post. You should NOT blindly use this to create all the missing indexes. This collects the details over time whenever the queries are run. So it all depends on the frequency of the queries that are run and the improvement by adding the missing index. Adding indexes adds the maintenance overhead which was mentioned in my previous blog post. I hope I answered your question.
Regards,
Manu
Thanks..