One of the important tasks when optimizing a SQL Server for performance is to find and convert heaps to clustered index. A HEAP is a messy collection of rows piled up unevenly. This does makes insert faster however, select/update/delete are very slow. On the other hand, Clustered index arranges the table as B-Tree structure based on the clustered index key value. A best practice is to have clustered index defined for a table unless it’s a very small one say a list of countries, states etc. Given below is a T-SQL to find tables without clustered index.
USE ADVENTUREWORKS2014
GO
SELECT tables.NAME,
(SELECT rows
FROM sys.partitions
WHERE object_id = tables.object_id
AND index_id = 0 -- 0 is for heap
-- 1 is for clustered index
)AS numberofrows
FROM sys.tables tables
WHERE Objectproperty(tables.object_id, N'TableHasClustIndex') = 0
The query uses OBJECTPROPERTY command to check whether a table in sys.tables view has a clustered index or not. A value of 1 indicates that table has clustered index and 0 indicates that it doesn’t has a clustered index.
The query returns number of rows each of the heaps contains so as to select a clustered index candidate. Another deciding factor is the table usage, which can be obtained from sys.dm_db_index_usage_stats dmv as shown below
USE ADVENTUREWORKS2014
GO
SELECT tables.NAME,
(SELECT rows
FROM sys.partitions
WHERE object_id = tables.object_id
AND index_id = 0 -- 0 is for heap
-- 1 is for clustered index
)AS numberofrows,
ius.last_user_scan As TableScan,
ius.last_user_lookup As RIDlookup
FROM sys.tables tables
LEFT JOIN sys.dm_db_index_usage_stats ius
ON tables.object_id=ius.object_id and ius.index_id=0
WHERE Objectproperty(tables.object_id, N'TableHasClustIndex') = 0
The above query gets the last_user_scan and last_user_lookup date for a particular. This tells how frequently the table is being used in queries. Thus, if a table has fairly large number of rows and is being accessed frequently, then it’s a good candidate to create clustered index. The output from above query is shown below.
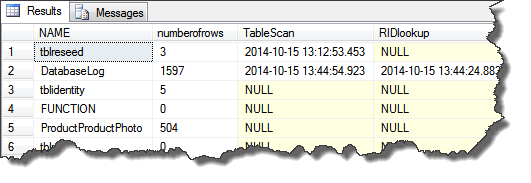
As shown in above snapshot, the table databaselog was recently scanned and a RIDlookup was performed on it too. This data can be recorded and analyzed over a period to decide whether or not to create clustered index on particular tables. The tables with null values against tablescan and RIDLookup column doesn’t exists in sys.dm_db_index_usage_stats dmv and are not being used recently.
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook