A common task for DBAs/Developers is to find duplicates in tables to avoid redundancy and storage misuse. Here is a T-SQL script to find duplicates.
Create table tblDup(Sno int identity, Col1 varchar(50))
GO
INSERT into tbldup
values('Value1'),('Value1'),('Value1'),
('Value2'),('Value2'),('Value2'),
('Value3'),('Value3'),('Value4'),('Value5')
GO
-- Query 1: CTE
;WITH CTE
AS
(
SELECT sno,col1,ROW_NUMBER() OVER(partition by col1 Order by sno) As RowNum
FROM tblDup
)
SELECT * from Cte
GO
-- Query 2: SubQuery
SELECT * FROM
( Select ROW_NUMBER() OVER(partition by col1 Order by sno) As Rno ,sno,col1 FROM tblDup ) tblsub
The Queries above uses row_number() function to number the values in col1 so that each of the unique set of values is assigned numbers starting from 1.For example, Value1 appears thrice so it is numbered from 1-3 and Value3 appears twice appears twice so it is number 1-2 as shown in below snapshot.
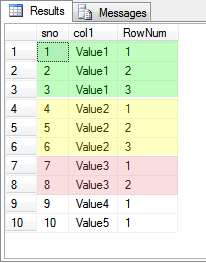
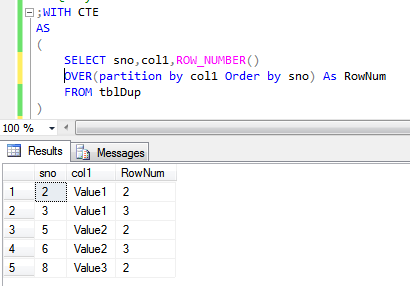
In order to get duplicate values we just need to query the CTE/subquery for values of RowNum > 1 as shown below.
Like us on FaceBook | Join the fastest growing SQL Server group on FaceBook