This article first appeared in the SQLServerGeeks Magazine.
Author: Jason M. Anderson
Subscribe to get your copy.
Cryptographic verification in Azure SQL Database ledger
In the above article, I covered the basics of the ledger feature of Azure SQL Database and explained how we employed a blockchain data pattern in SQL to protect data from potential tampering. I covered at a very high-level the process of verifying the database, which is in effect the process for detecting tampering that may have occurred. This article we’ll dive a bit deeper on the verification process and how it works.
Hashing and database digests
Let’s re-visit some basic concepts we discussed in the August edition related to Azure SQL Database ledger.
1. Rows updated in a transaction are SHA-256 hashed
2. Using a Merkle tree data structure, a root hash (HRoot) is calculated representing all rows updated
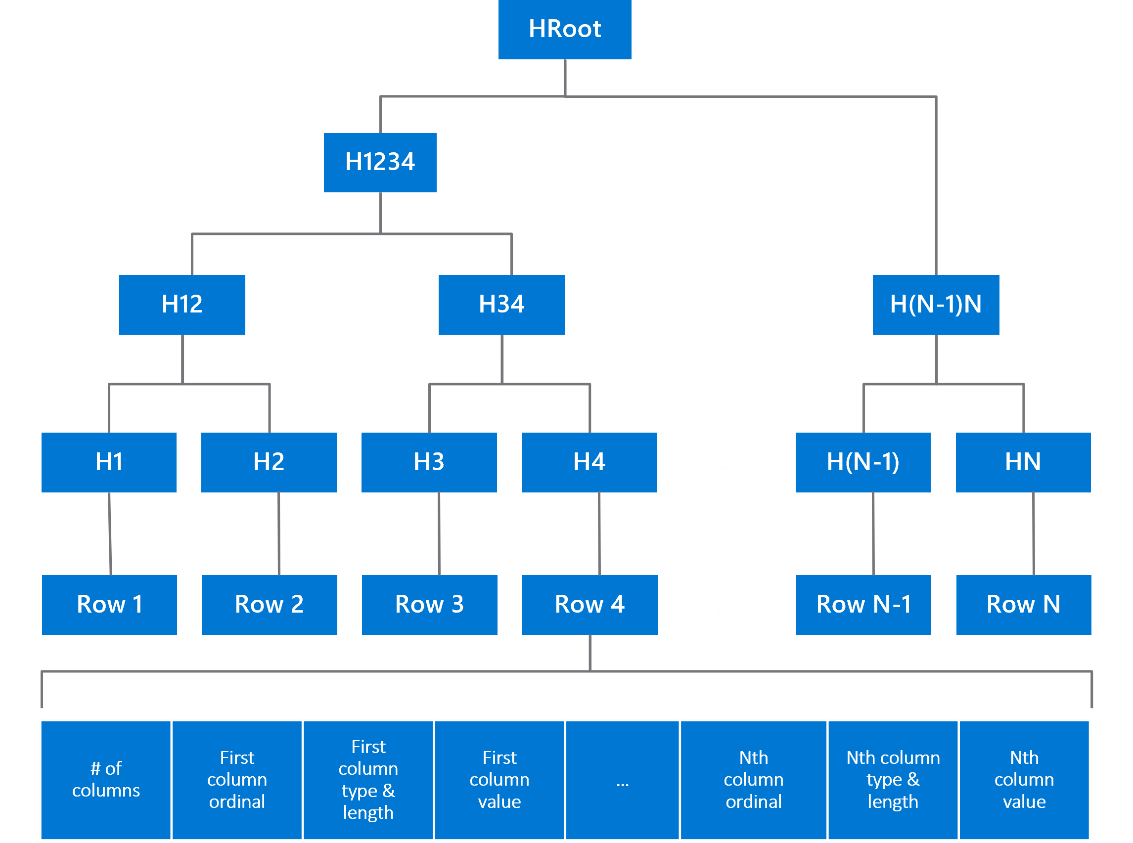
3. Transactions within the time period of a block (30 seconds), are hashed in a similar manner to rows
a. The Merkle root hash calculated from the rows is used as input to the hash function when hashing each transaction
4. The Merkle root hash of transactions in a block, along with the hash of the previous block, are used as input to calculate the hash for the current block
5. The hash for each block subsequently represents the state of the data in the database at the time the block is produced

Since the hash of each block represents the state of the database at the time it was produced, it is used to later verify the database, or more directly, to detect if tampering has occurred. As such, it’s important that the hashes themselves, are protected from tampering. To achieve this, Azure SQL Database ledger packages the hash, along with associated metadata, as a .JSON file (called a database digest), and pushes the database digest of each block to tamper-proof storage services; namely Azure blob Storage with a configured immutability policy, or Azure Confidential Ledger.
An example of a database digest is as follows:
{
"database_name":"myledgerdatabase",
"block_id":146816,
"hash":"0x48B0E6E8DEF42E68E451591C03361C93758A8975E9F0066BDE80
11D6BB08B396",
"last_transaction_commit_time":"2021-09-14T20:53:10.4833333",
"digest_time":"2021-09-14T20:53:11.0206521"
}
If an attacker changes any data in the database once a database digest is published, calculating the hashes in the database at that point in time will result in differing hash values than what is stored in tamper-proof storage. So how do you detect if tampering has happened, namely re-calculating the hashes of the database? The answer is database verification.
Database verification
Having the ability to prove to another party that data in your database has not been maliciously tampered is extremely powerful. In fact, you should think of the value of Azure SQL Database ledger not being to detect tampering, but rather proving that it has not been tampered with. For example, being able to provide an auditor or a regulator, cryptographic proof that your data has not been maliciously altered, provides a level of assurance that was not previously possible. In the event your data has been tampered with, being able to identify said tampering along with the capability of restoring the data to its original state, is a necessity.
Database verification in Azure SQL Database ledger is done through executing either sys.sp_verify_database_ledger or sys.sp_verify_database_ledger_from_digest_storage (based on how you’re storing your database digests – will cover this further in the article), passing as input the database. During database verification, the SQL server performs the following functions:
1. Re-calculates the hashes of all data stored in the database (or alternatively, a single table in the database that you want to verify)
2. Compares the re-calculated hashes during the verification process against the values of the hashes stored in the database digests that are referenced in the verify database stored procedure
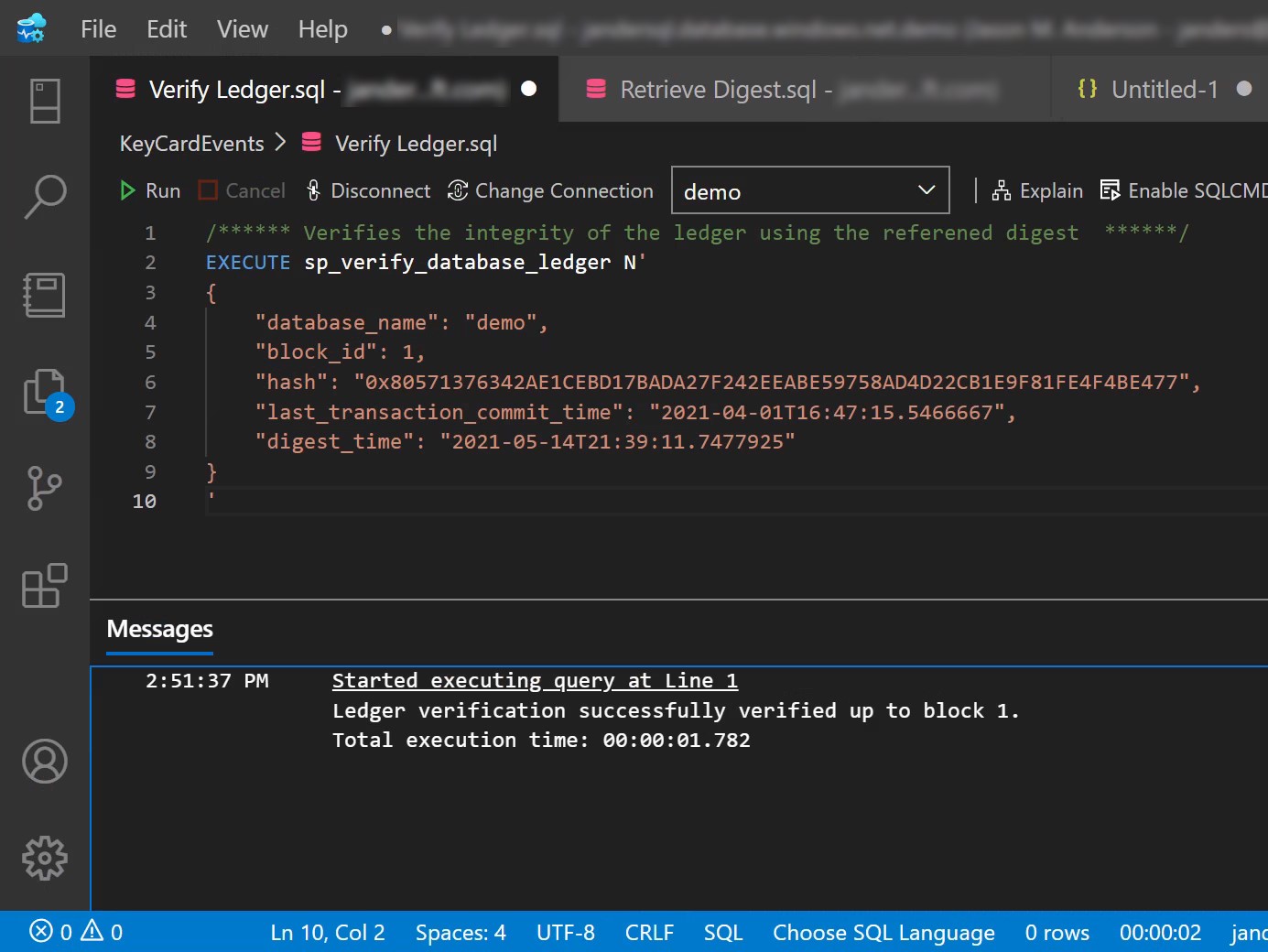
3. If the re-calculated hashes match the hashes stored in the database digests, the stored procedure executes successfully, with a message similar to the following
Started executing query at Line 1 (1 row affected) Ledger verification successfully verified up to block 3. (1 row affected) Total execution time: 00:00:00.997
4. If the re-calculated hashes do not match the hashes stored in the database digests, the stored procedure fails, with a message similar to
Msg 37368, Level 16, State 1, Procedure sp_verify_database_ledger, Line 1 The hash of block 3 in the database ledger does not match the hash provided in the digest for this block. Msg 37392, Level 16, State 1, Procedure sp_verify_database_ledger, Line 1 Ledger verification failed. Total execution time: 00:00:00.799
Database digest storage & the verification process
Depending on how you choose to store your database digests will impact how you run the verification process. By using the built-in capabilities of Azure SQL Database ledger to connect to either Azure Storage or Azure Confidential Ledger, you don’t have to “manage” anything. Digests are automatically created every 30 seconds and stored in the configured location. To then verify the integrity of the database, simply execute the following T-SQL script.
DECLARE @digest_locations NVARCHAR(MAX) = (SELECT * FROM
sys.database_ledger_digest_locations FOR JSON AUTO, INCLUDE_NULL_VALUES);
SELECT @digest_locations as digest_locations;
BEGIN TRY
EXEC sys.sp_verify_database_ledger_from_digest_storage
@digest_locations;
SELECT 'Ledger verification succeeded.' AS Result;
END TRY
BEGIN CATCH
THROW;
END CATCH
What we’re doing here is fetching the location of digests and simply running the verification stored procedure passing the @digest_locations to fetch the database digests.
If instead you choose to store your database digests yourself, a little more work is involved (though not a ton). You’ll first need to generate database digests manually. This simply involves executing sp_generate_database_ledger_digest, no arguments are necessary. This will essentially produce a
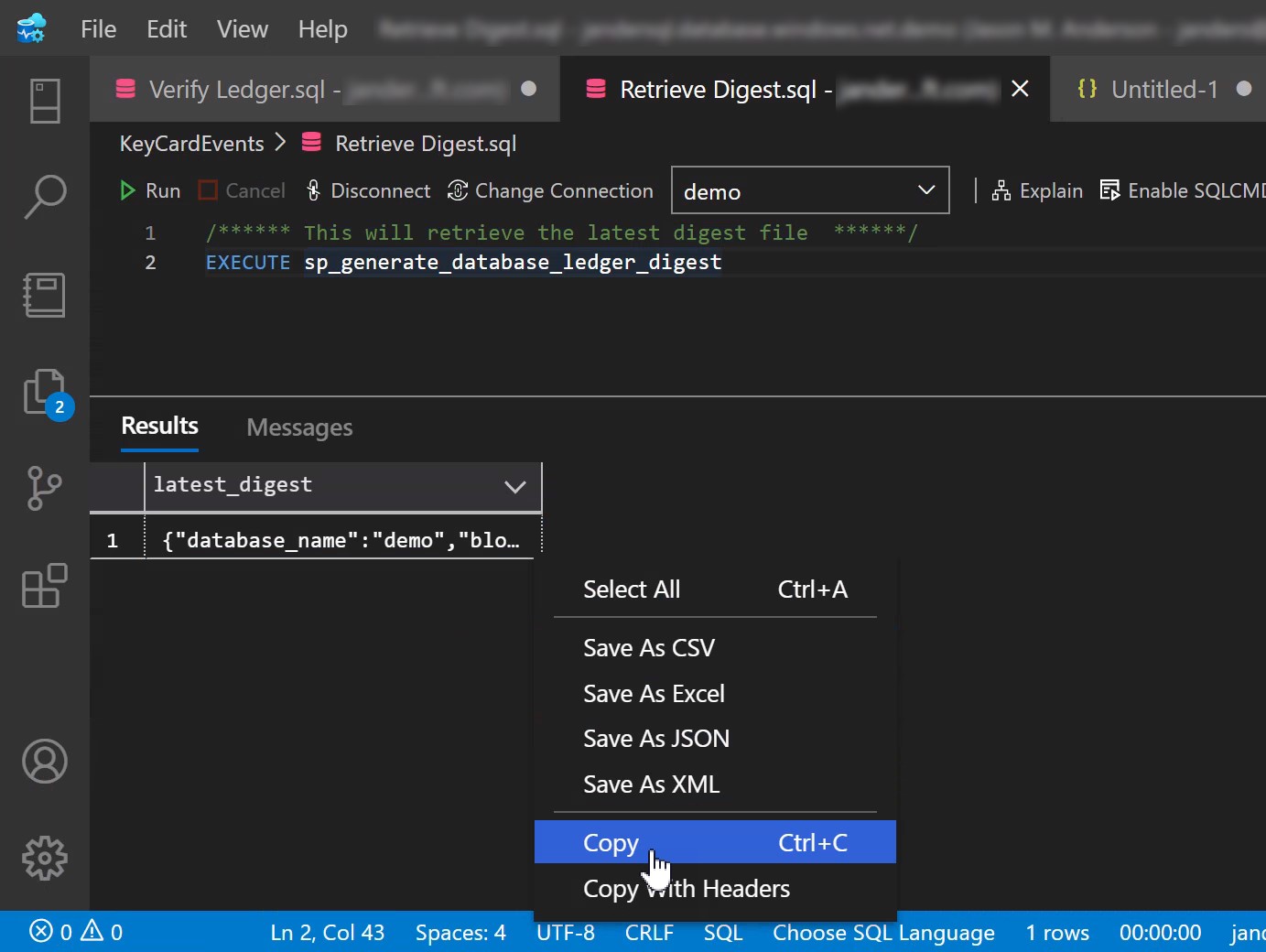
block, containing the hash of all rows/transactions that have occurred since the last time the stored procedure was executed, presented as a resultset.
Simply copy the contents of the resultset, save it to the location of your choice as a .JSON document. As you generate more digests, add the contents of the resultsets to the existing .JSON document you have as it will simplify running verification.
Verifying the database then requires executing sp_verify_database_ledger passing the contents of your digest(s) for verification.
Database digests are about 250 bytes, so very small from a storage costs perspective – even if you’re generating digests frequently, such as every 30 seconds.
The verification process, however, is an expensive process to execute. The time for verification to execute, as in the simple example above for a single digest, completes in a manner of seconds. However, as your ledger grows and you accumulate thousands, or millions, of digests, the process of recomputing hashes for millions of rows can take upwards to an hour to complete. As such, you should think about executing database verification only when necessary, such as hourly for smaller databases, or daily for larger ones, and ideally during non-peak load times of your database as to not negatively impact query performance.
For more information and samples on digest generation, storage and database verification, see https://docs.microsoft.com/azure/azure-sql/database/ledger-verify-database
Have questions on Azure SQL Database ledger? Drop me an email at janders@microsoft.com or on Twitter @JasonMA_MSFT.
This article first appeared in the SQLServerGeeks Magazine.
Author: Jason M. Anderson
Subscribe to get your copy.
One Comment on “Azure SQL Database ledger PART 2 by Jason M. Anderson”