In today’s blog, we will be discussing the concept of selectivity.
For a SQL Server user who performs actions such as storing and recovering data on a daily basis as a developer or a DBA, the concept of selectivity might not be at the top of their priorities. Whereas, for someone who wants to dive deep into the internals of SQL Server engine and more importantly is involved in query tuning, concepts such as Predicates, Density Factor, Cardinality Estimation and of course Selectivity have a lot to bring to the game.
The prime focus of the blog will be selectivity. What it means, how it works and most importantly some misconceptions associated with the topic.
Selectivity can be stated to be the “measure of uniqueness” or “the number of rows matching the predicate divided by the total number of rows.”
Selectivity = No. of rows matching the predicate/Total number of rows
A simple example using predicates can help better understand the concept of selectivity.
We are using AdventureWorks2014 for the purposes of this blog. In AdventureWorks2014, there is a table called sales.SalesOrderDetail in the sales schema. Let’s look at the no of rows in this table.
USE AdventureWorks2014 GO SELECT COUNT(*) FROM Sales.SalesOrderDetail
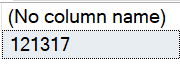
There are 121317 rows in the table SalesOrderDetail.
Now, a predicate is applied to filter all entries with an ID of 43659.
SELECT * FROM Sales.SalesOrderDetail WHERE SalesOrderID = 43659
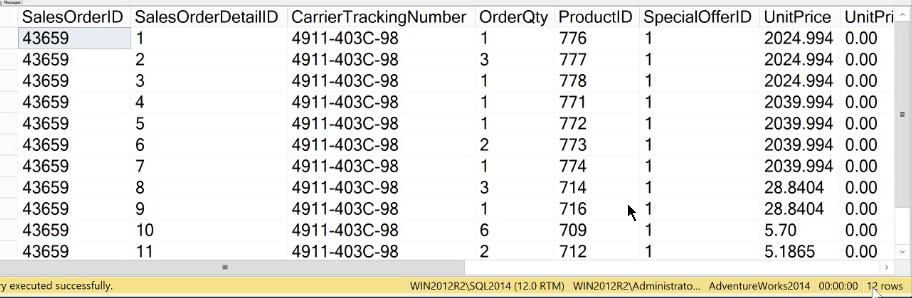
The Status bar shows the result set having 12 records. Appling this to the formula we get the following result.
Selectivity = 12/121317
= 0.00009891
It is to be noted that the number of records returned are very low, making the query highly Selective. A query is said to have ‘high Selectivity’ if low number of records are returned that matched the predicate, whereas a query is said to have ‘low Selectivity’ if a large number of records are returned.
In order to understand low Selectivity, the previous query can be tweaked to display all entries that have an ID greater than 43659.
SELECT * FROM Sales.SalesOrderDetail WHERE SalesOrderID > 43659
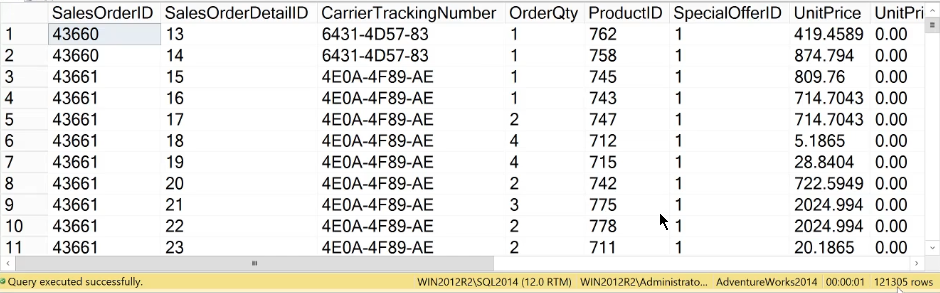
This query returns a result set containing 121305 rows. Applying this value in the formula, we get the following.
Selectivity = 121305/12137
= 0.99990108
A selectivity value of 1 means that all rows of the table are being returned. One of the primary misconceptions regarding this topic that must be clarified is data can never be high or low on selectivity. It is the query.
Let us look into an example to better understand this concept. A table named Product contains the master data for products, where every record in the table represents a product. There are a total of 504 records in the table.
SELECT * FROM Production.Product
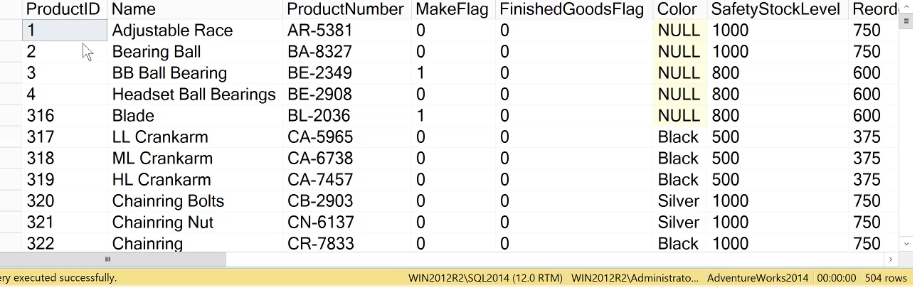
All the product IDs in the table are unique which makes the table highly unique, thus having a high value of selectivity.
Although, saying that the data is highly selective would still be incorrect in this case. This can be checked by running a couple more queries.
The query shown below returns all records containing an ID of 1.
There is only one record from a total of 504 rows, thus making the query highly selective.
SELECT * FROM Production.Product WHERE ProductID = 1
![]()
On changing the query with a different predicate that returns all entries whose ‘FinishedGoodsFlag’ value is 0, 209 rows are returned in the results set.
SELECT * FROM Production.Product WHERE FinishedGoodsFlag = 0
Upon using this value in the formula, we can obtain the value of selectivity as follows–
Selectivity = (209/504)*100
= 41.468200
This clearly shows that even when the data in the table (master or transactional) is the same, the values of selectivity may differ. This proves that the data in itself does not determine selectivity, but instead it is the query that that defines it.